Transform Data with EMR
Transform Data with EMR
This is an optional module. In this module, we will use Amazon EMR to send pyspark jobs to read the primitive data and do some transformations + aggregation and save the results back in S3.
Copy script to S3
- In this step, we will move to the S3 Console and create some folders to use for the EMR step.
- Go to: S3 Console
- Add PySpark script:
- Open yourname-analytics-workshop-bucket
- Click Create folder
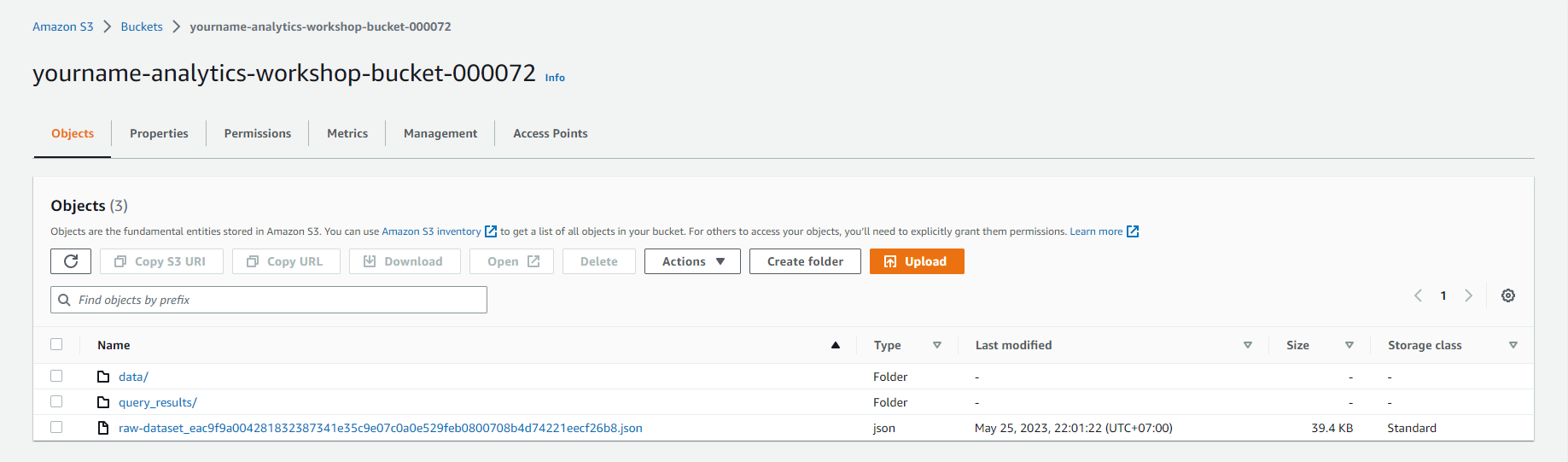
- Create a new folder named scripts
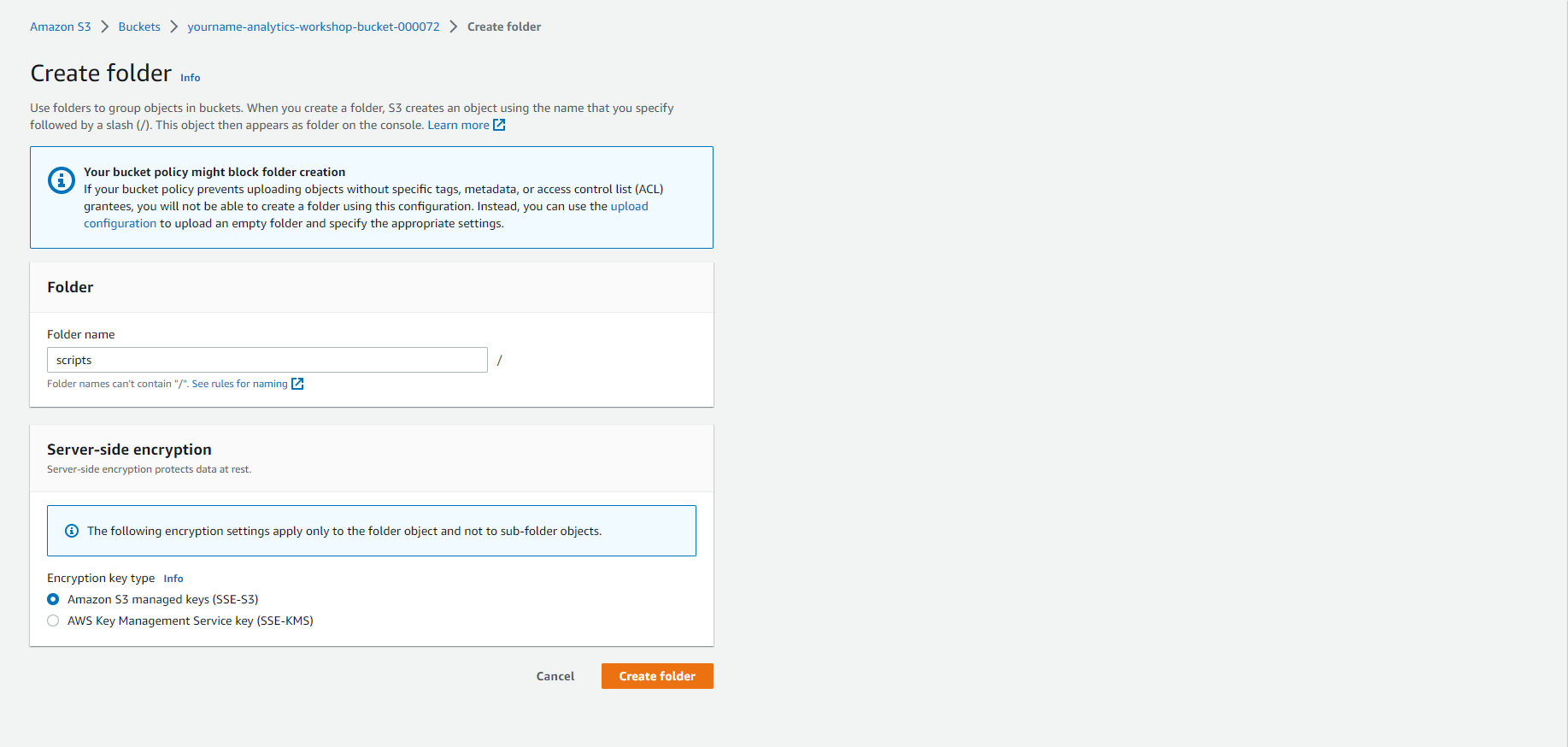
- Open the scripts folder
- Download this file to your local machine: [emr_pyspark.py](https://static.us-east-1.prod.workshops.aws/public/7072e03f-04ad-4825-87ca-0eab704a7e83/static/scripts/emr_pyspark .py) or Github
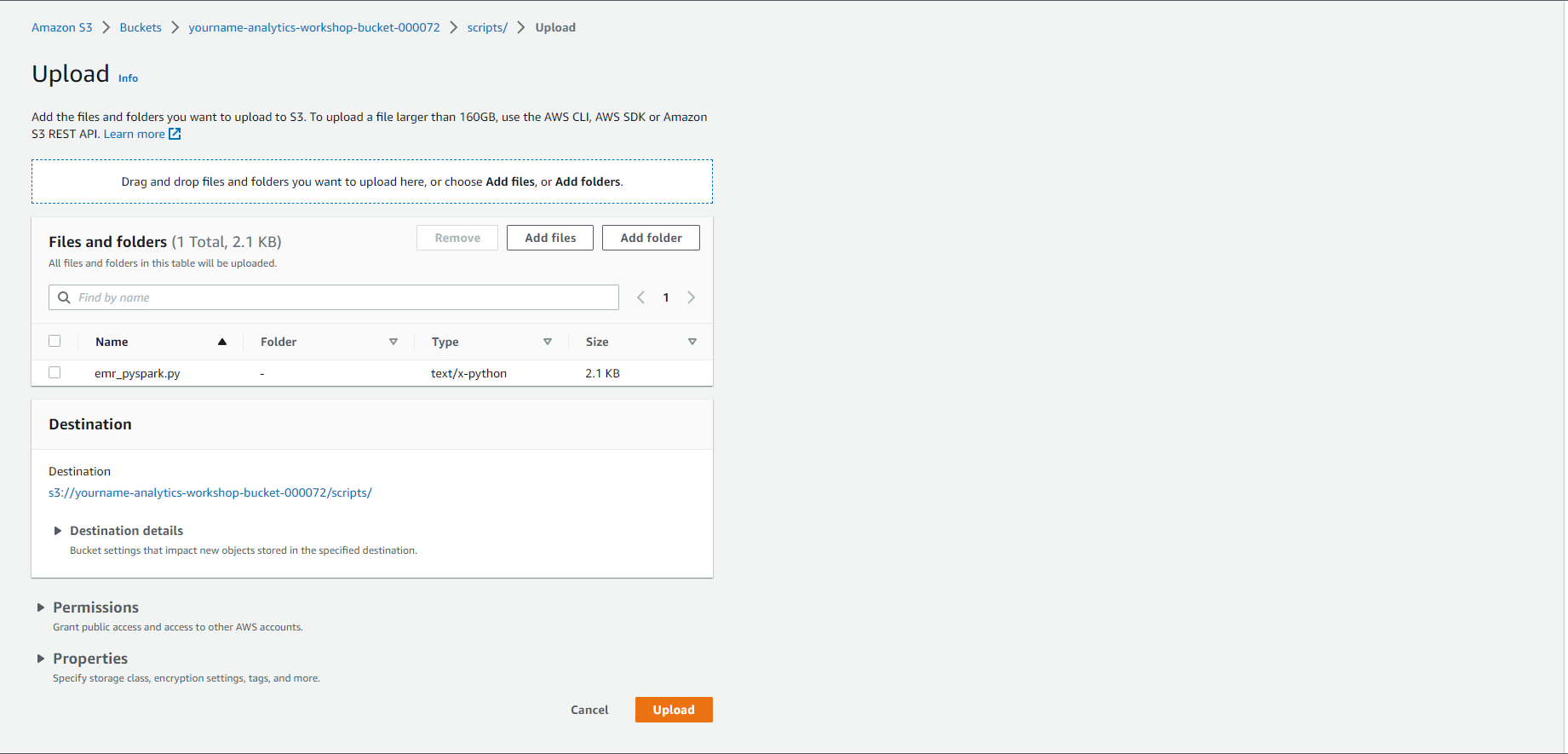
- In the S3 console, click Upload:
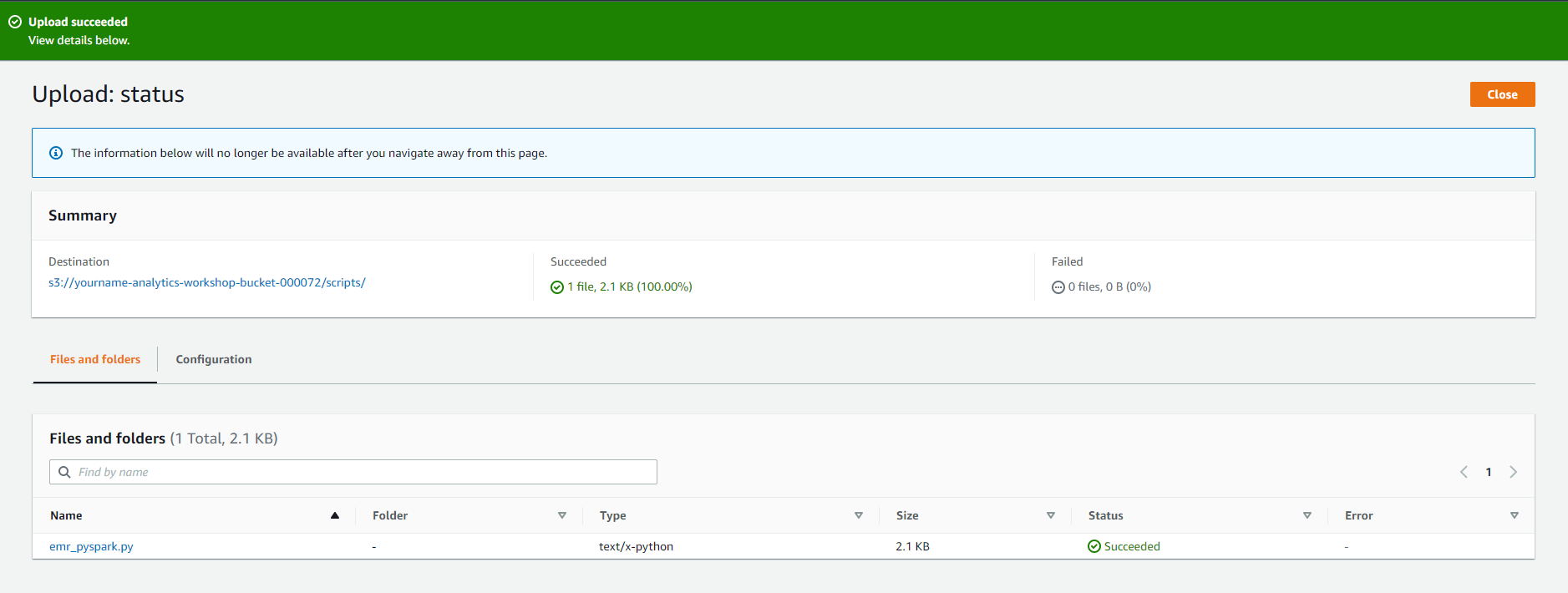
- Click Add files and Upload the emr_pyspark.py file you just downloaded
- Click Upload
- Create a directory for EMR logs:
- Open yourname-analytics-workshop-bucket
- Click Create folder
- Create a new folder named logs. Click Save
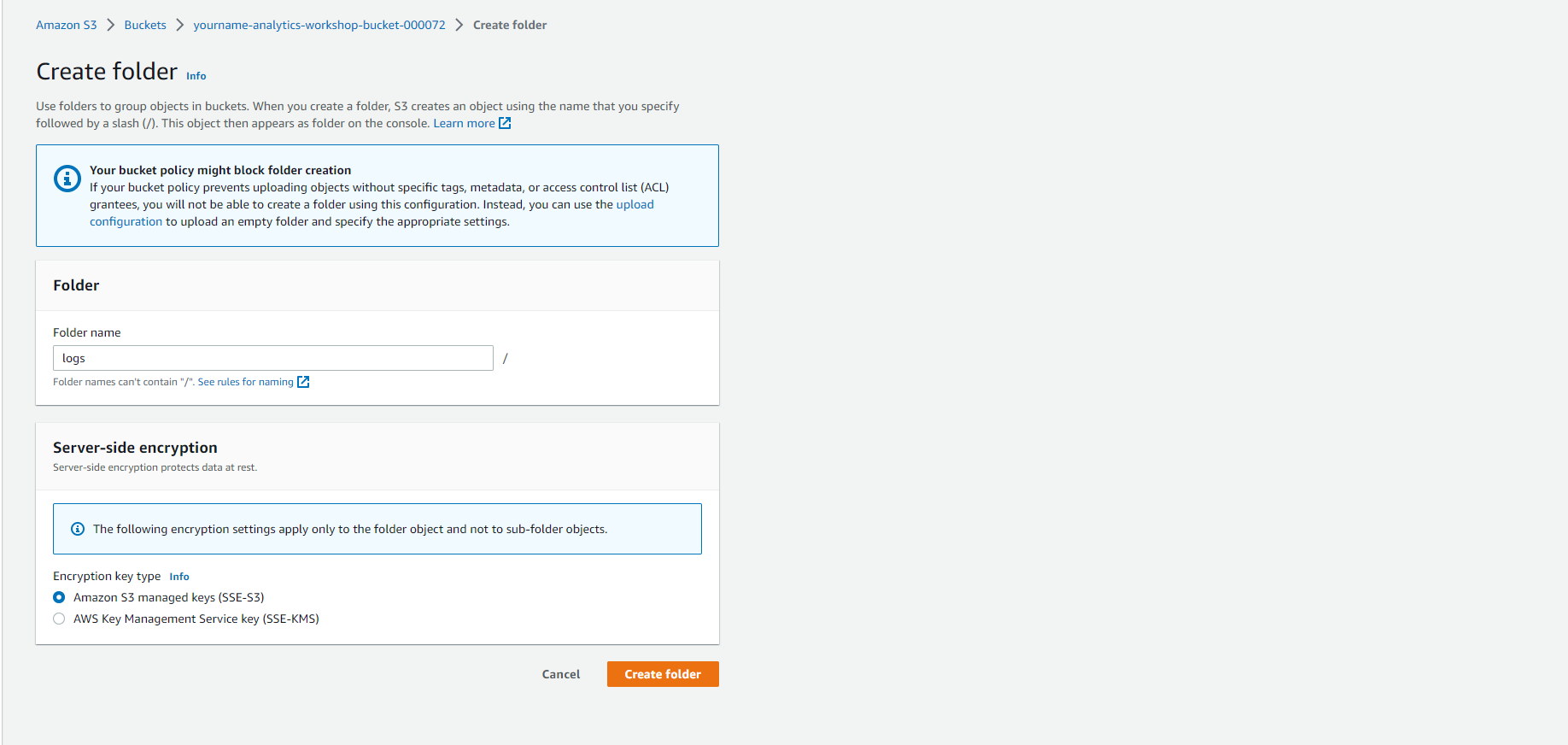
Create EMR cluster and add step
In this step, we will create an EMR cluster and send a Spark step.
- Go to the EMR console:
- Select Create cluster
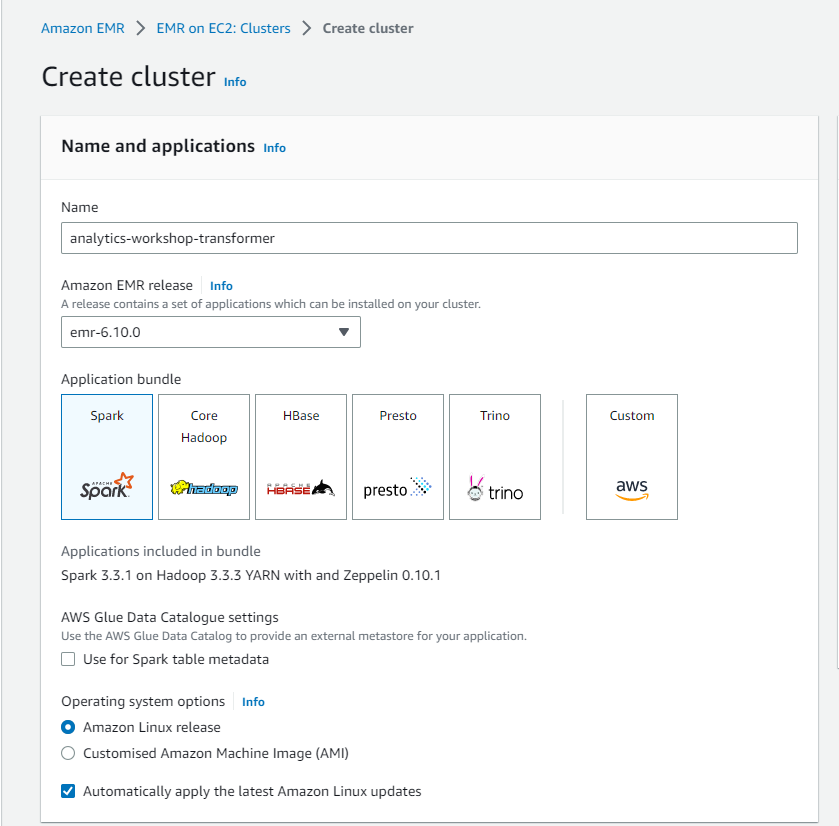
- Name and application:
- Name: analytics-workshop-transformer
- Amazon EMR release: default (e.g.: emr-6.10.0)
- Application bundle: Spark
- Install AWS Glue Data Catalog: Uncheck Use for Spark table metadata
- Leave other settings as default.
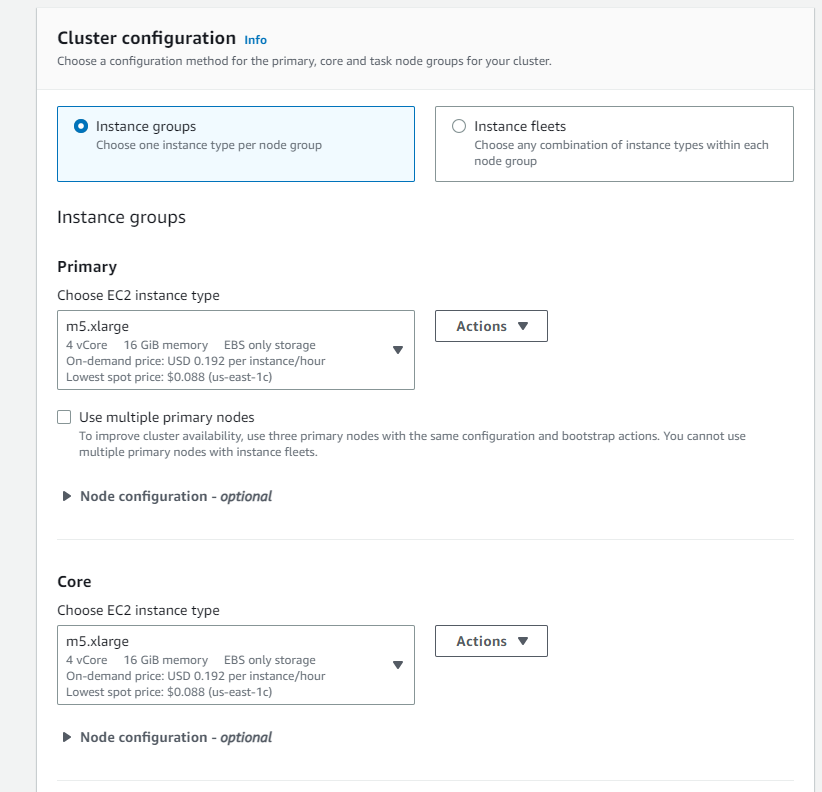
- Cluster configuration:
- Choose Instance groups
- Leave Primary, Core and Task to default value (m5.xlarge)
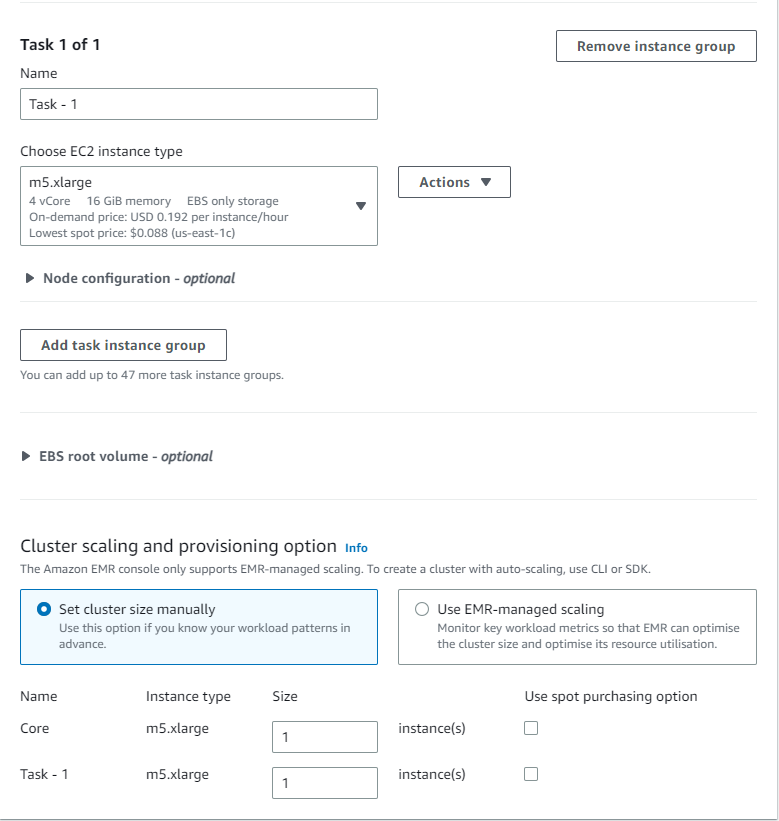
- Leave Cluster scaling and provisioning option to default (Core: size 1, Task -1: size 1)
- Networking: Leave to deafult
- Steps: Add
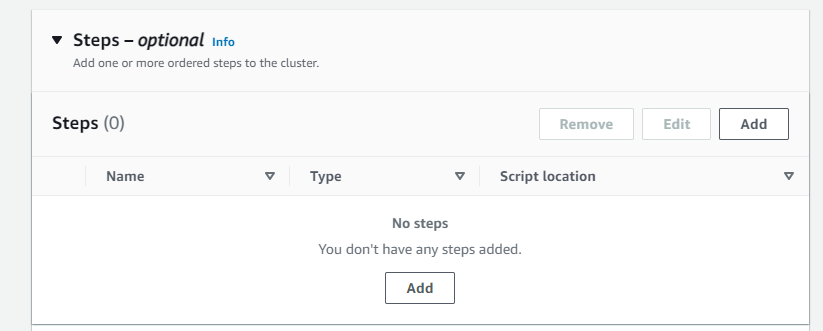
- Type: Spark application
- Name: Spark job
- Deploy mode: Cluster mode
- Application location: s3://yourname-analytics-workshop-bucket/scripts/emr_pyspark.py
- Arguments: enter the name of your s3 bucket yourname-analytics-workshop-bucket
- Action if step fails: Terminate cluster
- Click Save step

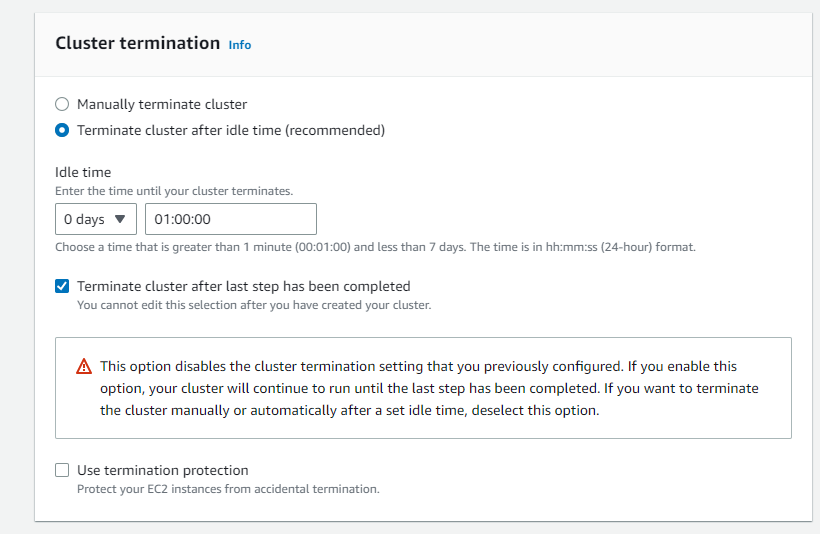
- Cluster termination
- Terminate cluster after idle time (Recommended)
- Idle time: 0 days 01:00:00
- Check Terminate cluster after last step completes
- Uncheck Use termination protection
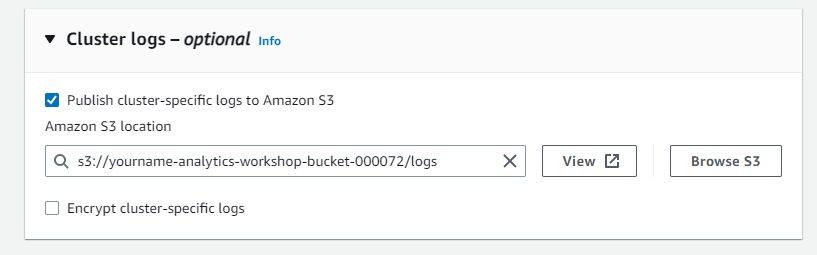
- Cluster logs:
- Check Publish cluster-specific logs to Amazon S3
- Amazon S3 location: s3://yourname-analytics-workshop-bucket/logs/
- Tags:
- Optionally add Tags, e.g.: workshop: AnalyticsOnAWS
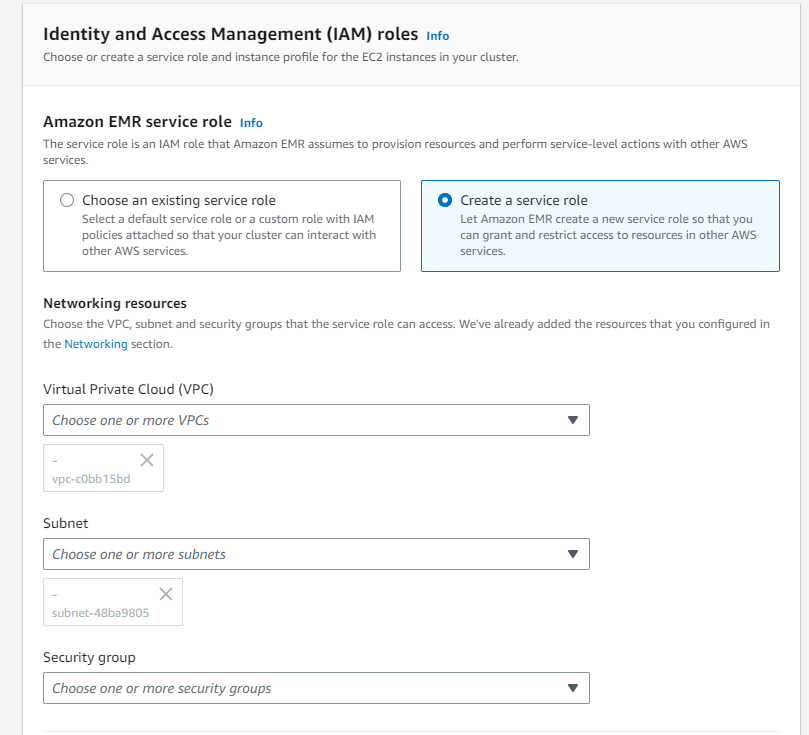
- Identity and Access Management (IAM) roles
- Amazon EMR service role: Create a service role
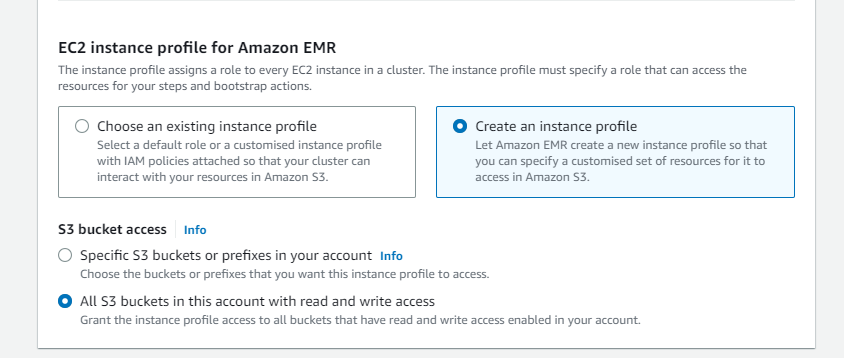
- EC2 instance profile for Amazon EMR: Create an instance profile
- S3 bucket access: All S3 buckets in this account with read and write access
- Click Create cluster
- Check the status of the Transform Job running on the EMR. EMR Cluster will take 6-8 minutes to prepare, and another minute to complete Spark step execution.
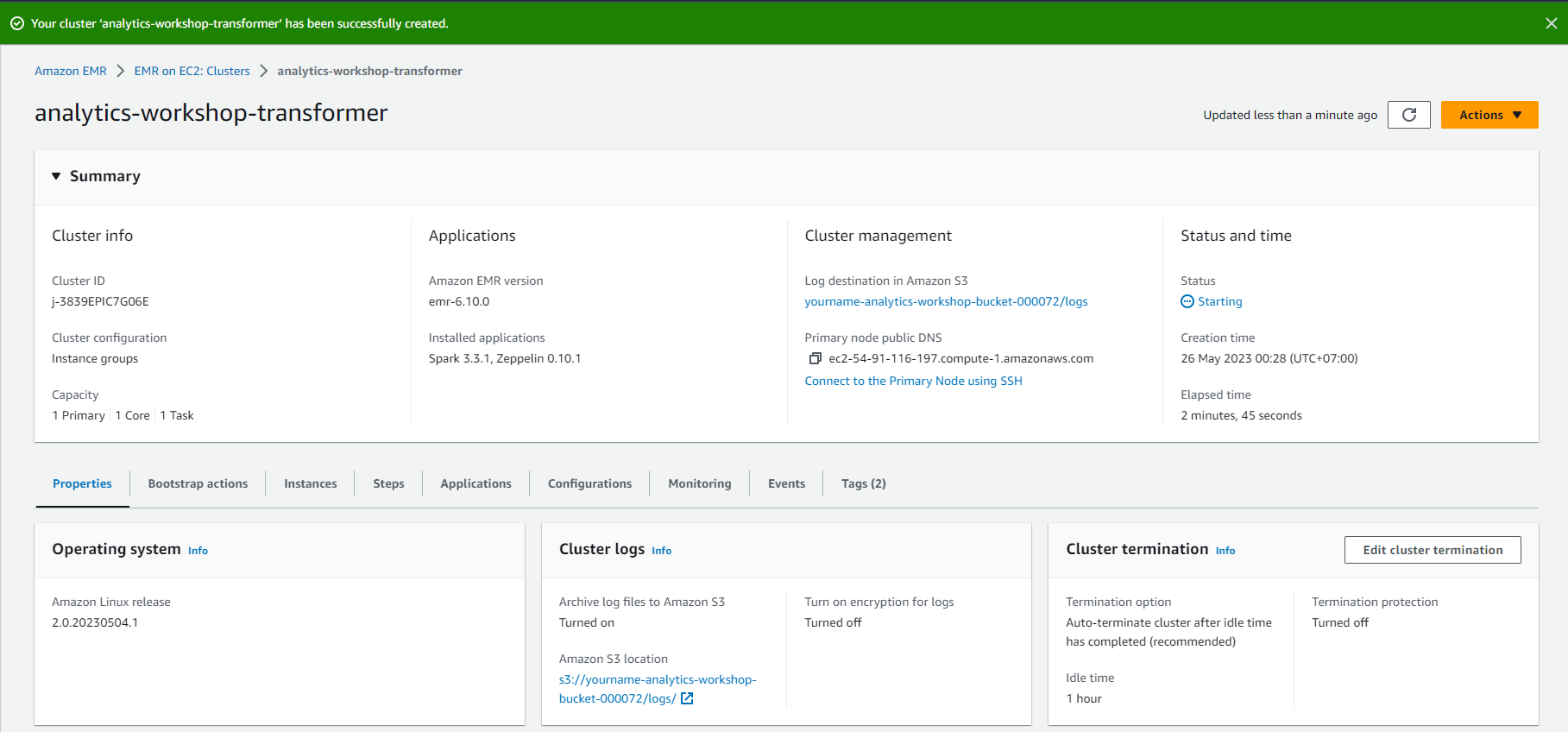
- Cluster will be terminated after Spark job is executed.
- To check the status of the job, Select the EMR Cluster name: analytics-workshop-transformer
- Go to Steps . tab
- Here you should see two entries: Spark application and Setup hadoop debugging
- The state of Spark application should change from Pending to Running to Completed.
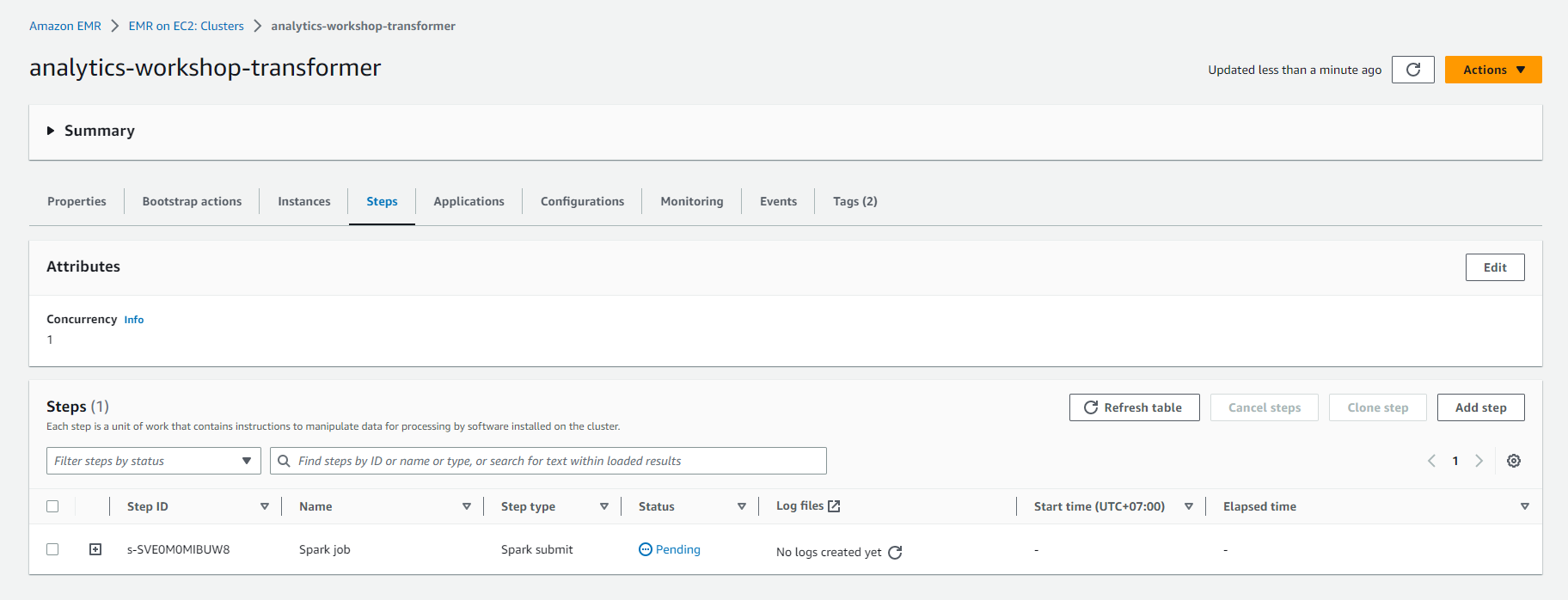
- After the Spark job is complete, the EMR cluster will be terminated.
- Under EMR > Cluster, you will see the Status of the cluster is “Terminated” with the message “All steps completed”.

Validate - Validated data has been sent to S3.
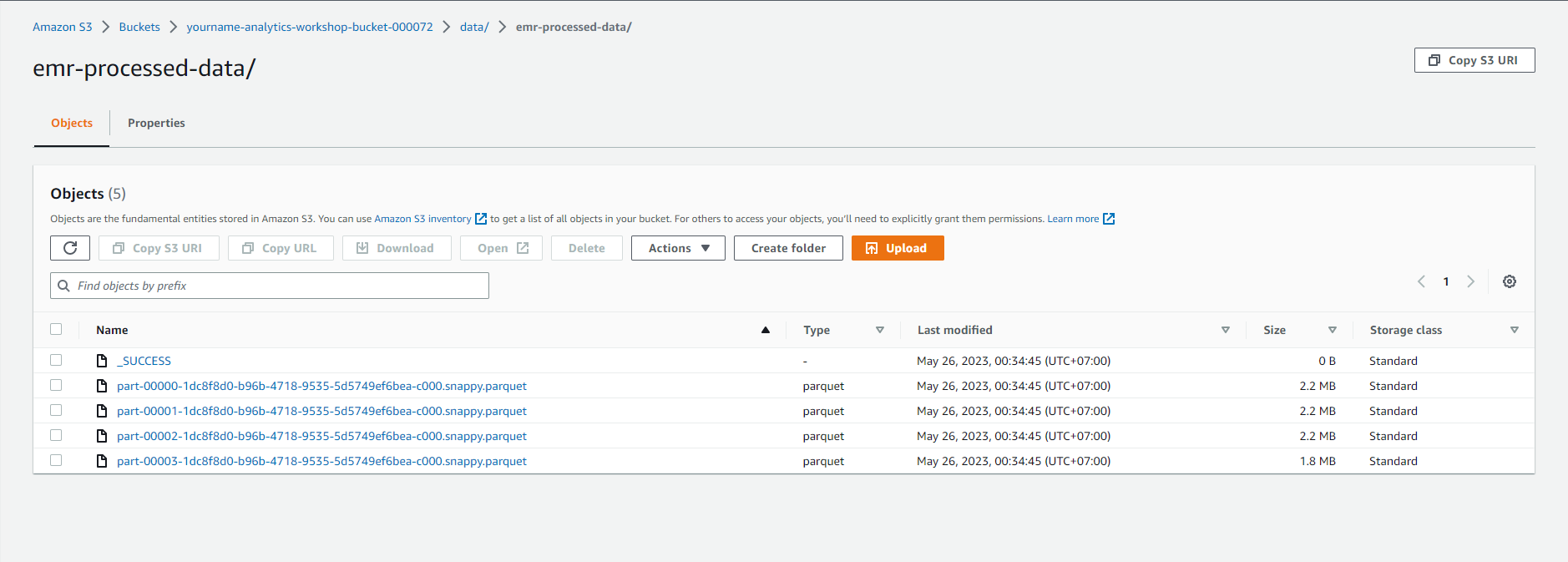
- Proceed to confirm that the EMR conversion job created the dataset in the S3 console: Click here
- Select - yourname-analytics-workshop-bucket > data
- Open new folder emr-processed-data:
- Make sure that the .parquet files have been created in this folder.
Rerun Glue Crawler
- Go to: Glue Dashboard
- On the left panel, Select Crawlers (Crawler Tools)
- Select the data collection tool created in the previous module: AnalyticsworkshopCrawler
- Select Run (Run)
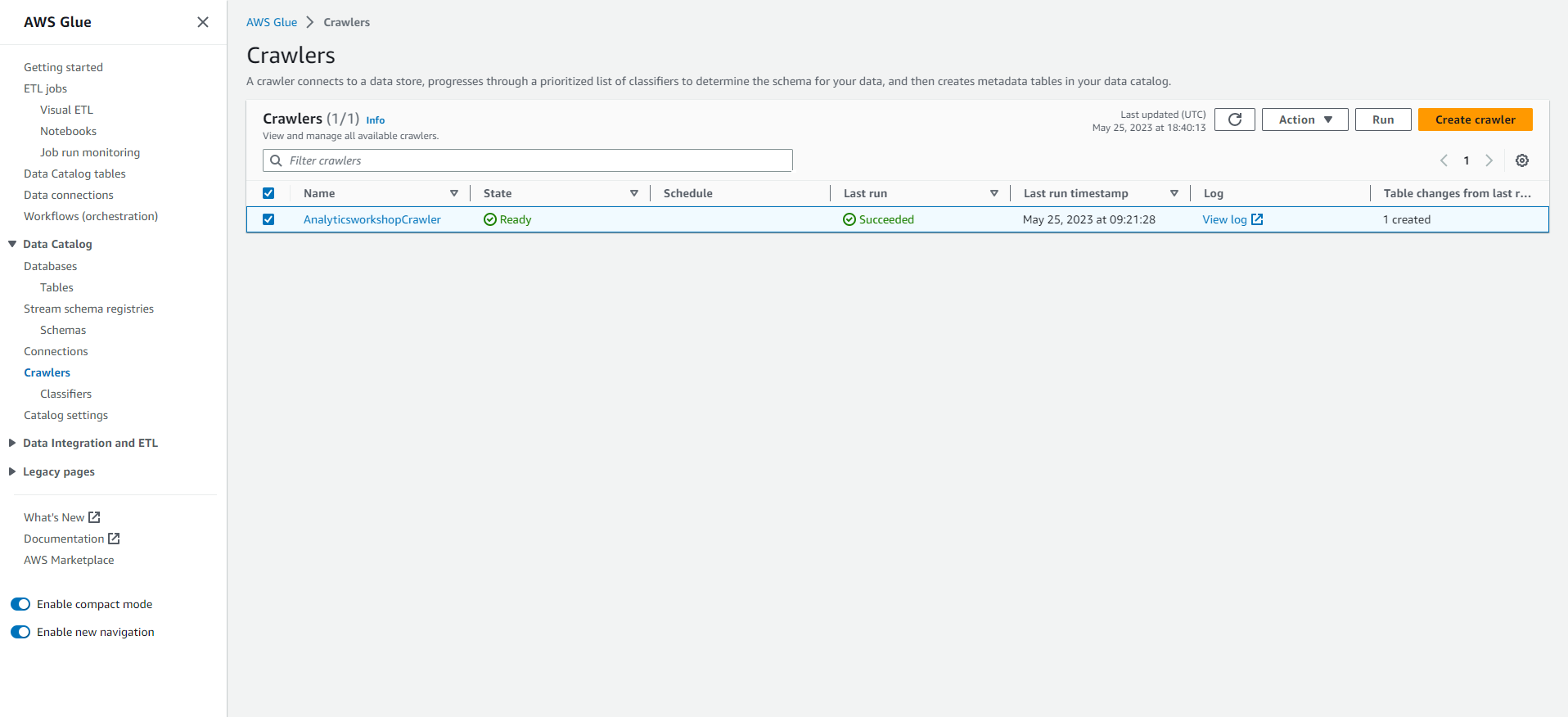
- You will see the Status change to Starting.
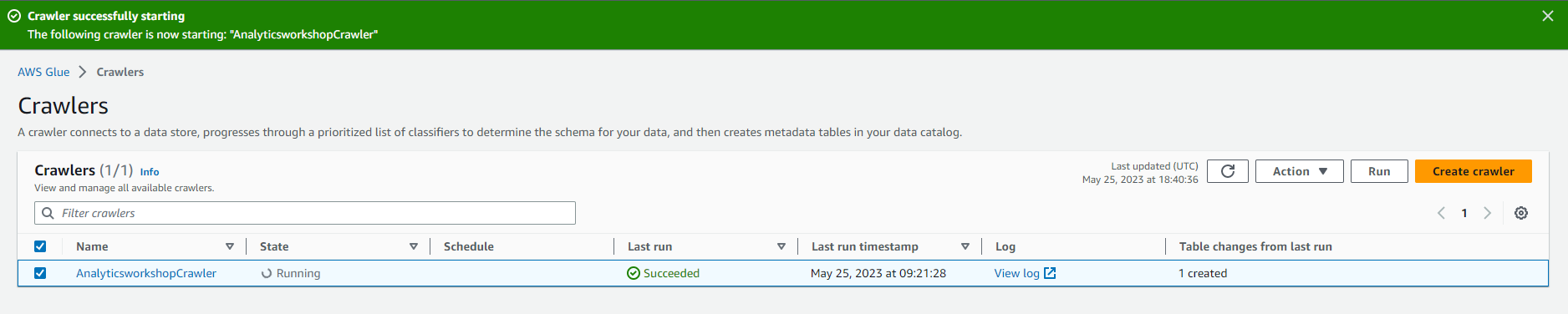
- Wait a few minutes for the crawl tool to complete. The data collection tool will display Tables added as 1.
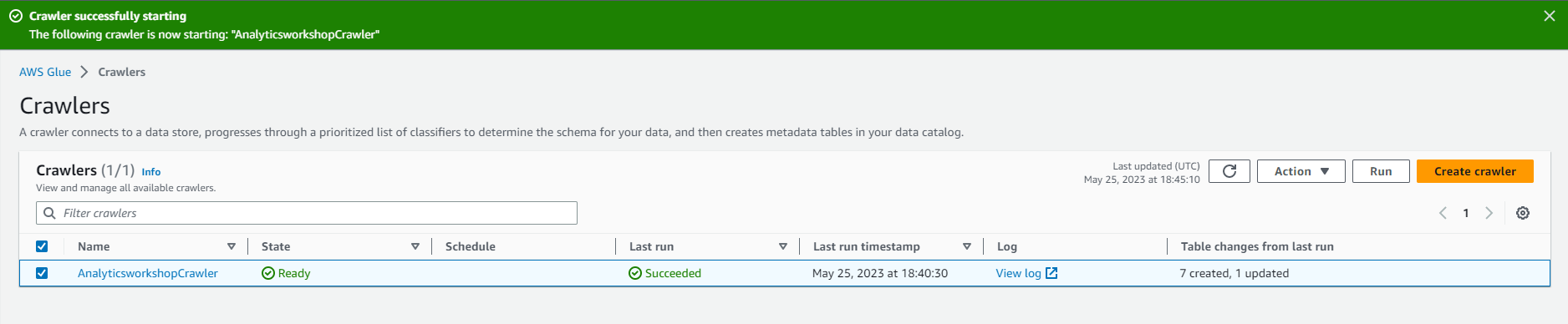
- You can go to the database section on the left and confirm that the emr_processed_data table has been added.
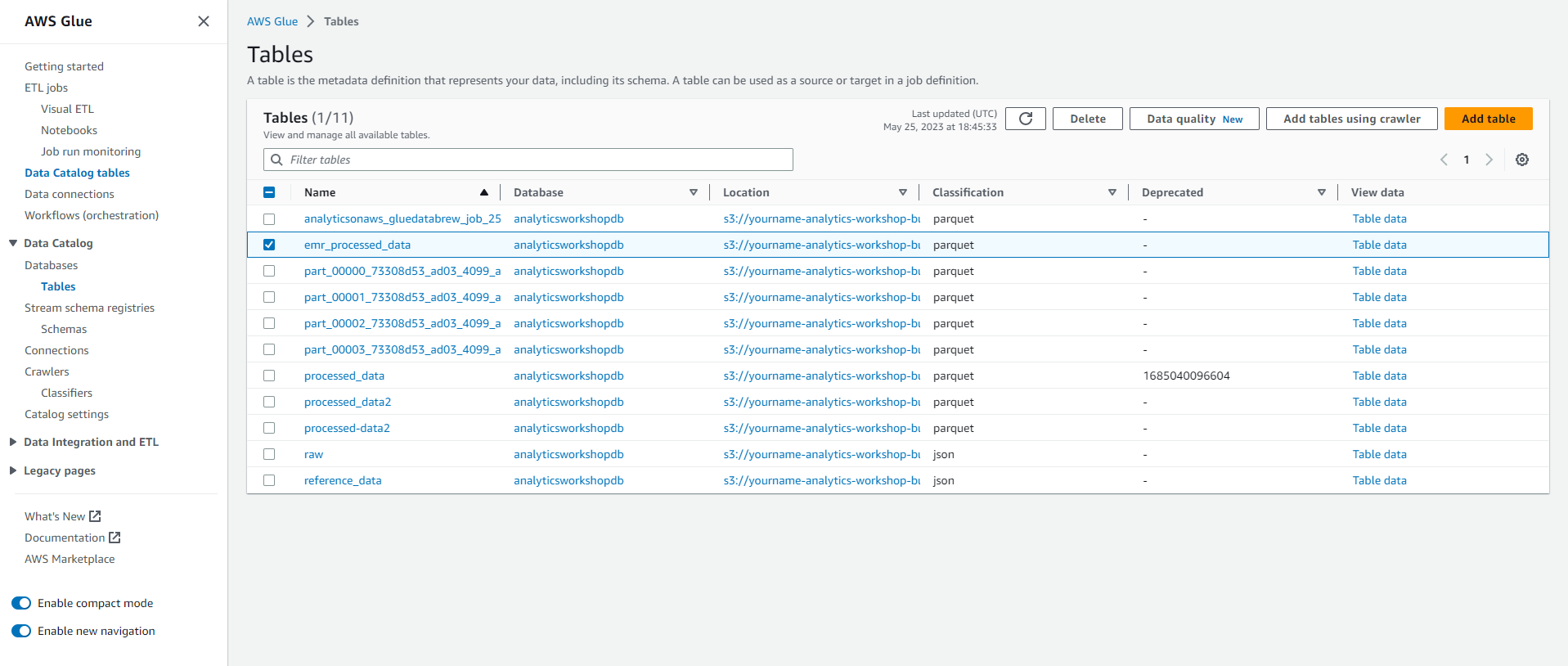
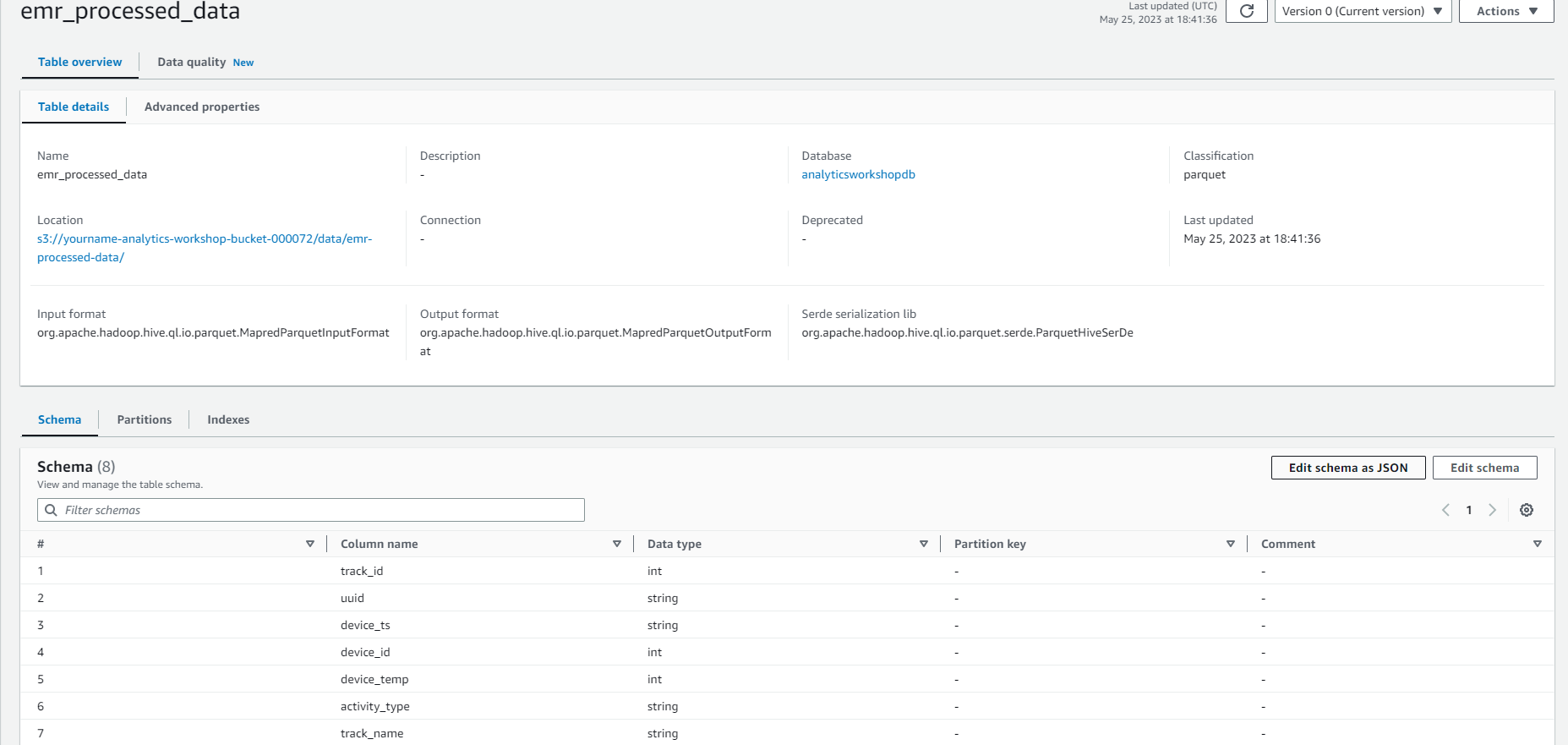
You can now query the results of the EMR job using Amazon Athena in the Next module.