Chuyển đổi dữ liệu bằng EMR
Chuyển đổi dữ liệu bằng EMR
Đây là một module tùy chọn. Trong module này, chúng ta sẽ sử dụng Amazon EMR để gửi các job pyspark để đọc dữ liệu nguyên thủy và thực hiện một số biến đổi + tổng hợp và lưu kết quả trở lại trong S3.
Sao chép script vào S3
- Trong bước này, chúng ta sẽ di chuyển đến S3 Console và tạo một số thư mục để sử dụng cho bước EMR.
- Đi đến: S3 Console
- Thêm PySpark script:
- Mở yourname-analytics-workshop-bucket
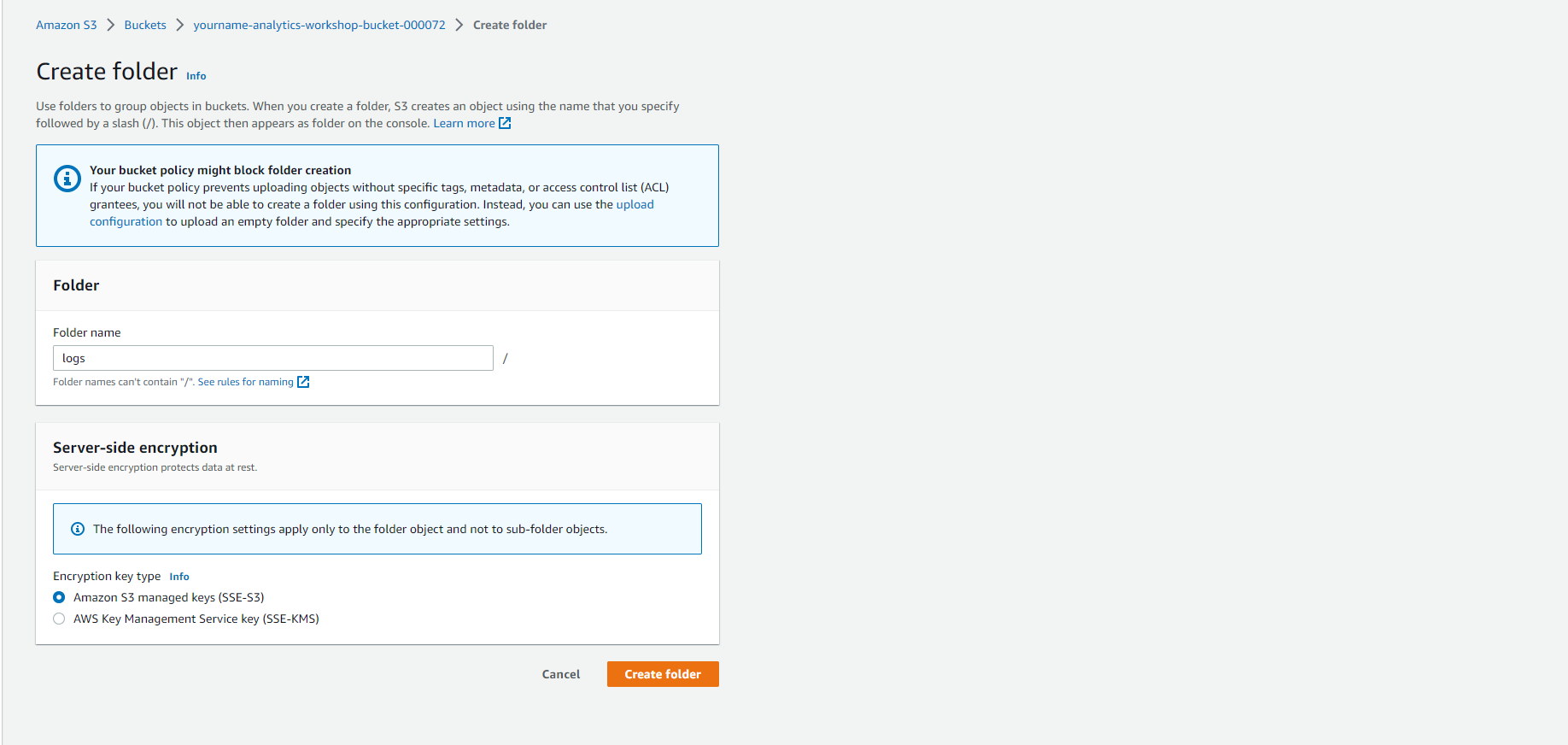
- Bấm Create folder
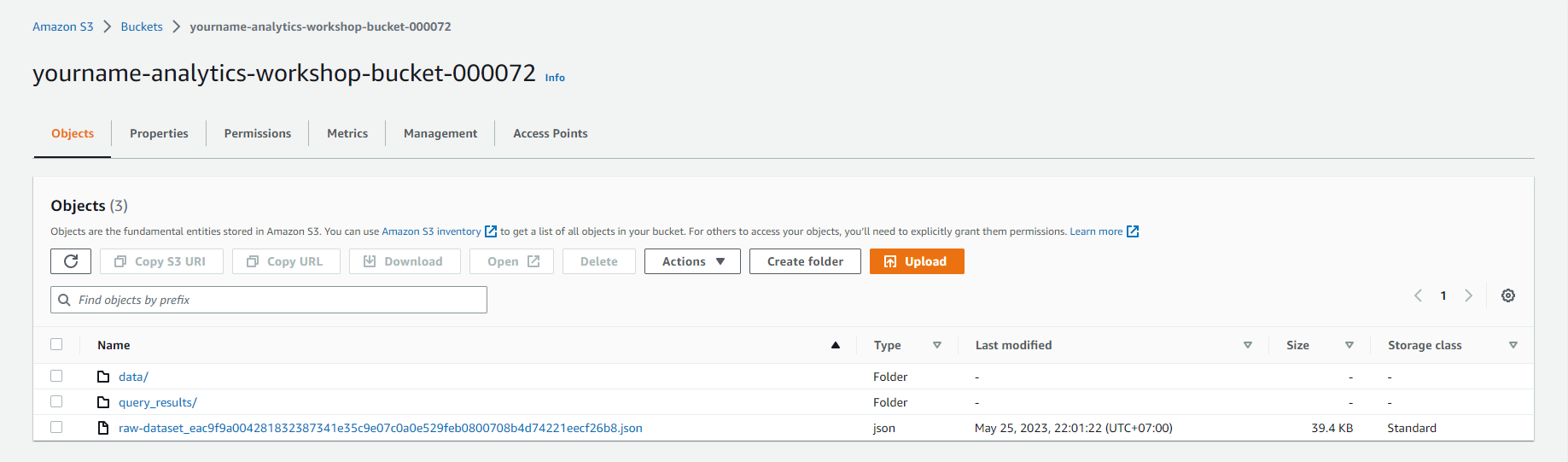
- Tạo một thư mục mới có tên là scripts
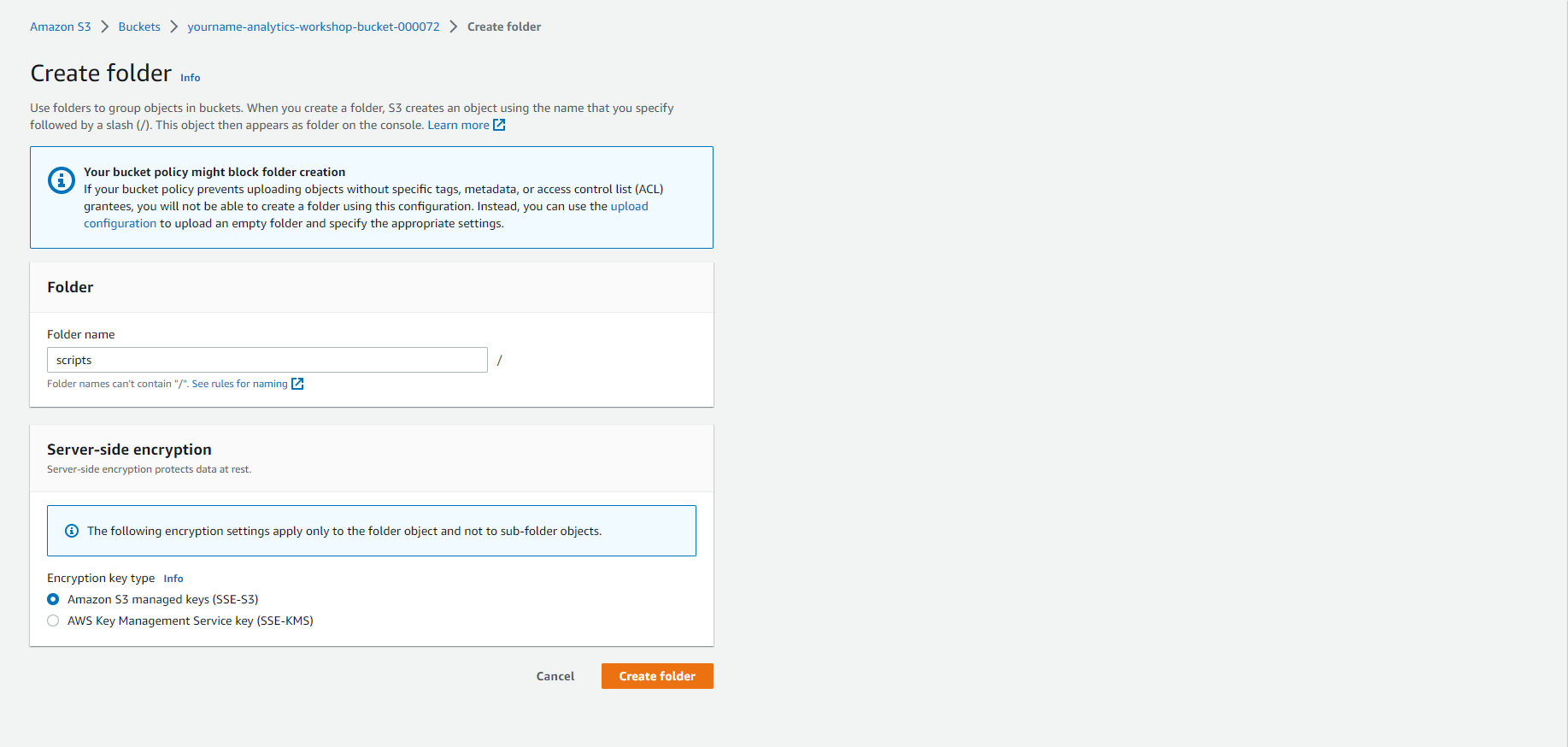
- Mở thư mục scripts
- Tải tệp này về máy cục bộ: emr_pyspark.py hoặc Github
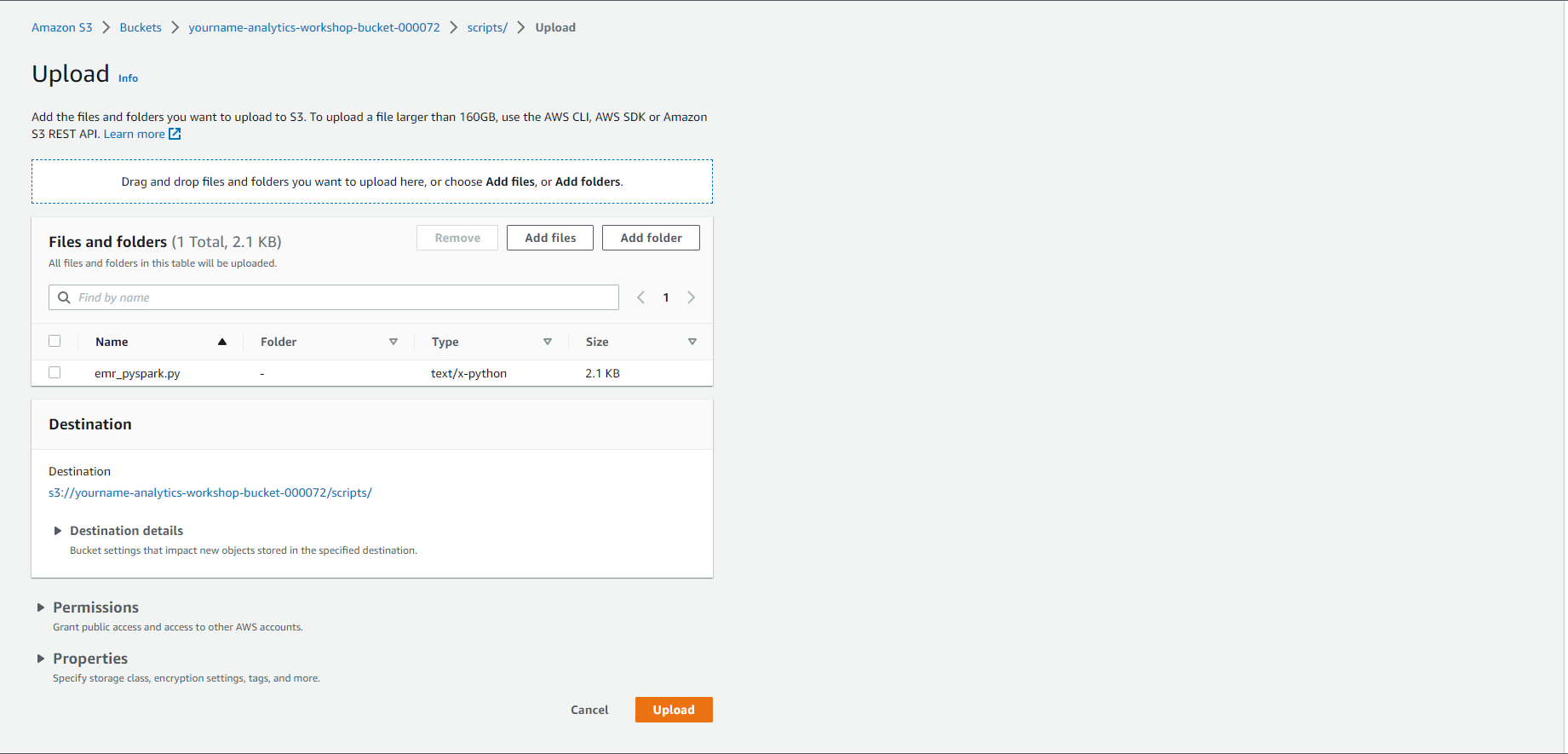
- Trong S3 console, bấm Upload:
- Bấm Add files and Upload tệp emr_pyspark.py bạn vừa tải xuống
- Bấm Upload
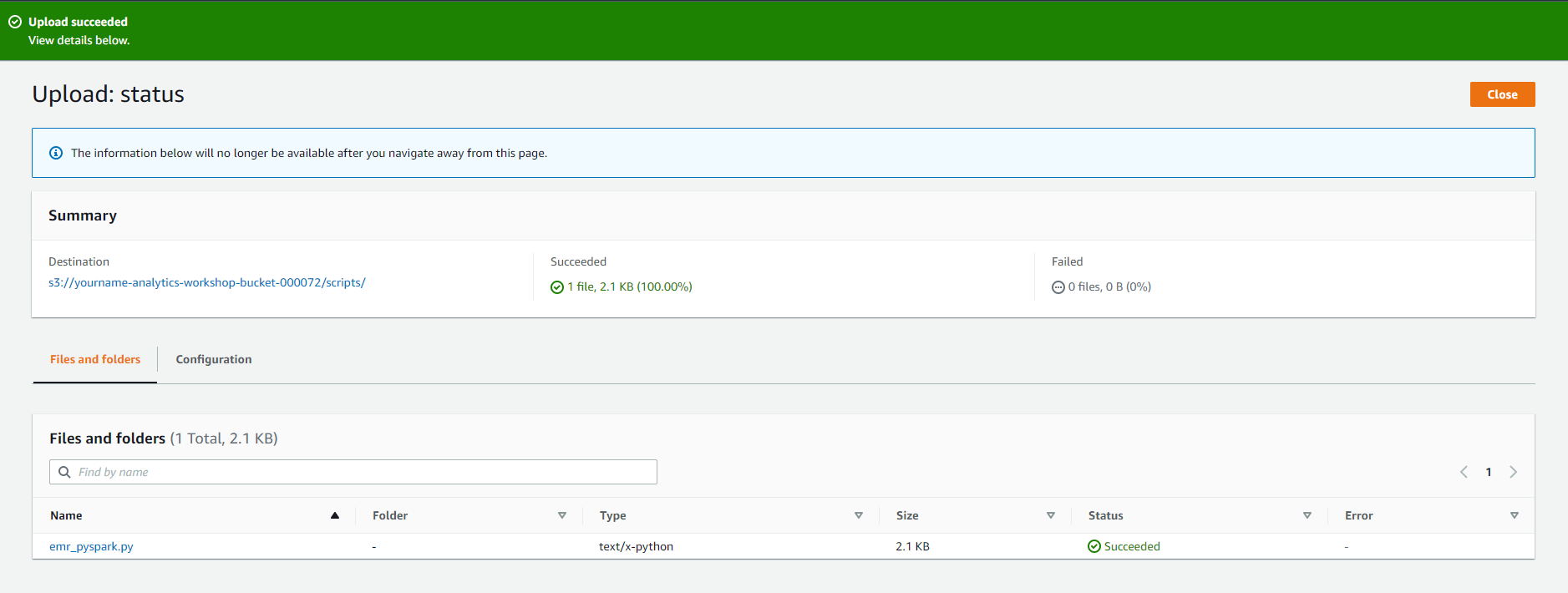
- Tạo một thư mục cho EMR logs:
- Mở yourname-analytics-workshop-bucket
- Bấm Create folder
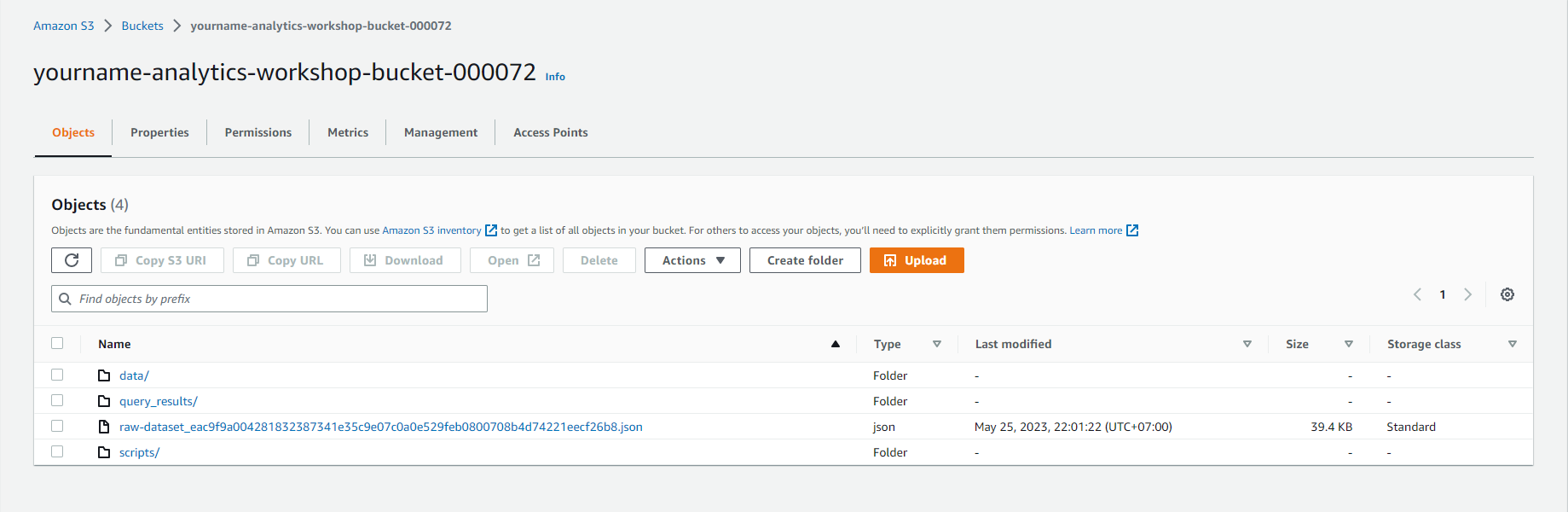
- Tạo một thư mục mới có tên là logs. Bấm Save
Tạo cụm EMR và thêm bước
Trong bước này, chúng ta sẽ tạo một cụm EMR và gửi một bước Spark.
- Đi đến bảng điều khiển EMR:
- Chọn vào Create cluster
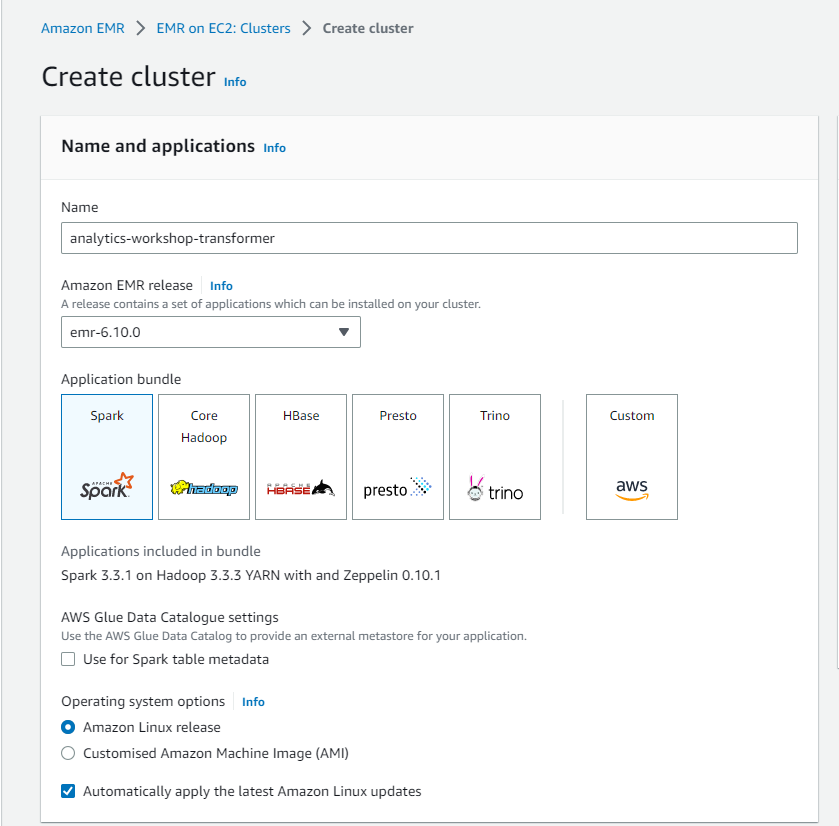
- Tên và ứng dụng:
- Name: analytics-workshop-transformer
- Amazon EMR release: default (e.g.: emr-6.10.0)
- Application bundle: Spark
- Cài đặt AWS Glue Data Catalog: Bỏ chọn Use for Spark table metadata
- Để các cài đặt khác mặc định.
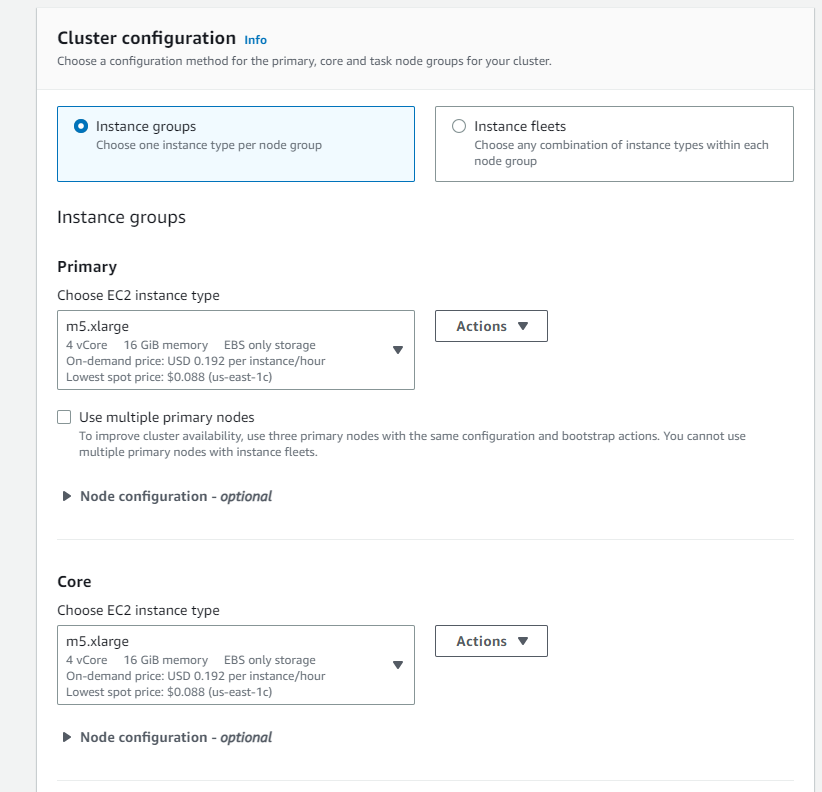
- Cluster configuration:
- Choose Instance groups
- Leave Primary, Core and Task to default value (m5.xlarge)
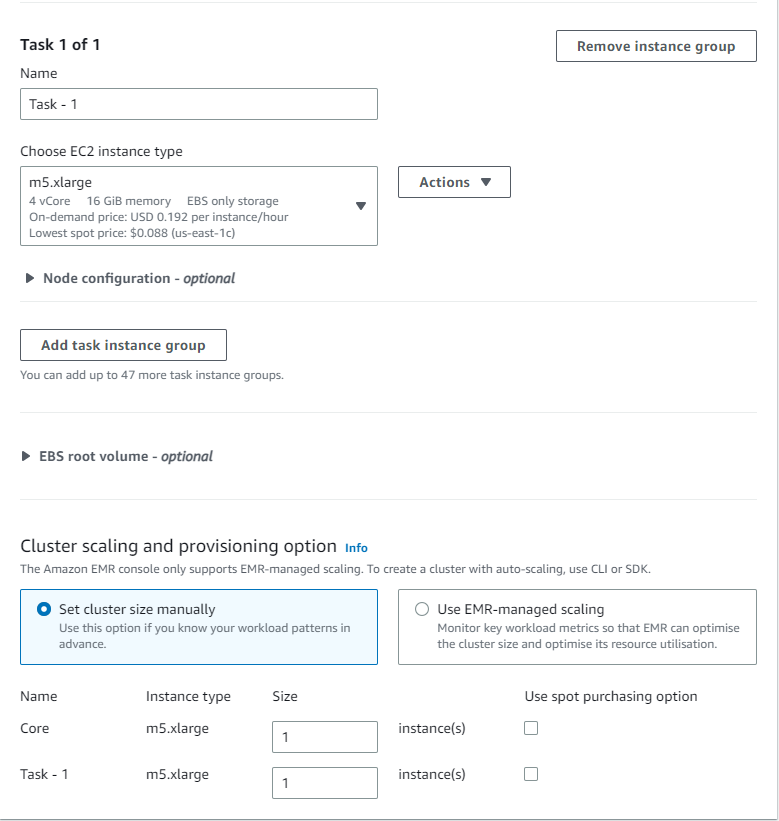
- Leave Cluster scaling and provisioning option to default (Core: size 1, Task -1: size 1)
- Networking: Leave to deafult
- Steps: Add
- Type: Spark application
- Name: Spark job
- Deploy mode: Cluster mode
- Application location: s3://yourname-analytics-workshop-bucket/scripts/emr_pyspark.py
- Arguments: enter the name of your s3 bucket yourname-analytics-workshop-bucket
- Action if step fails: Terminate cluster
- Click Save step

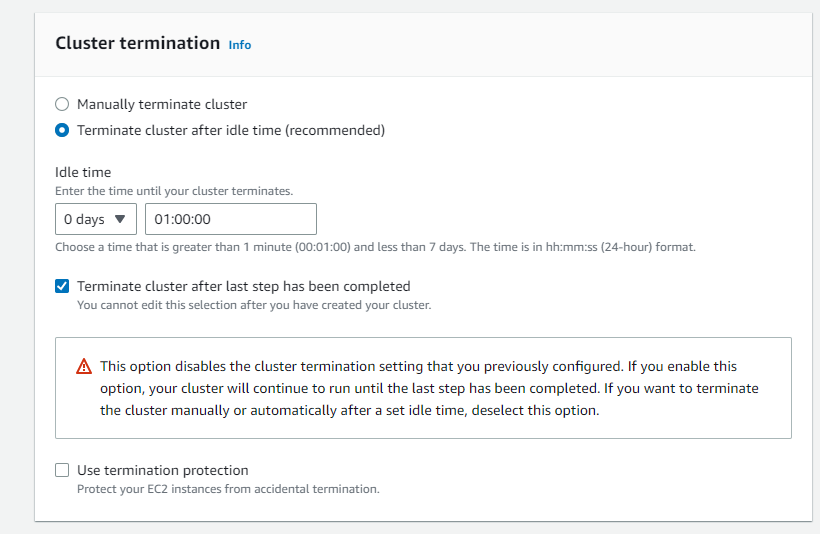
- Cluster termination
- Terminate cluster after idle time (Recommended)
- Idle time: 0 days 01:00:00
- Check Terminate cluster after last step completes
- Uncheck Use termination protection
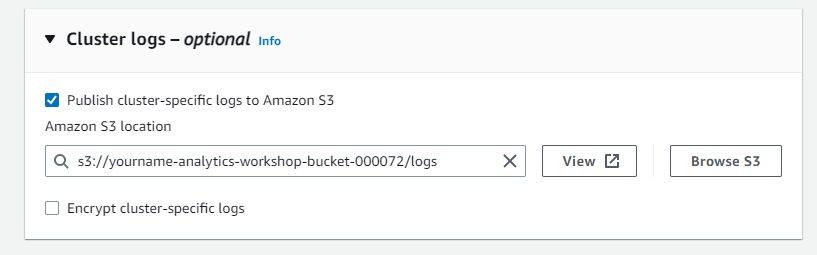
- Cluster logs:
- Check Publish cluster-specific logs to Amazon S3
- Amazon S3 location: s3://yourname-analytics-workshop-bucket/logs/
- Tags:
- Optionally add Tags, e.g.: workshop: AnalyticsOnAWS
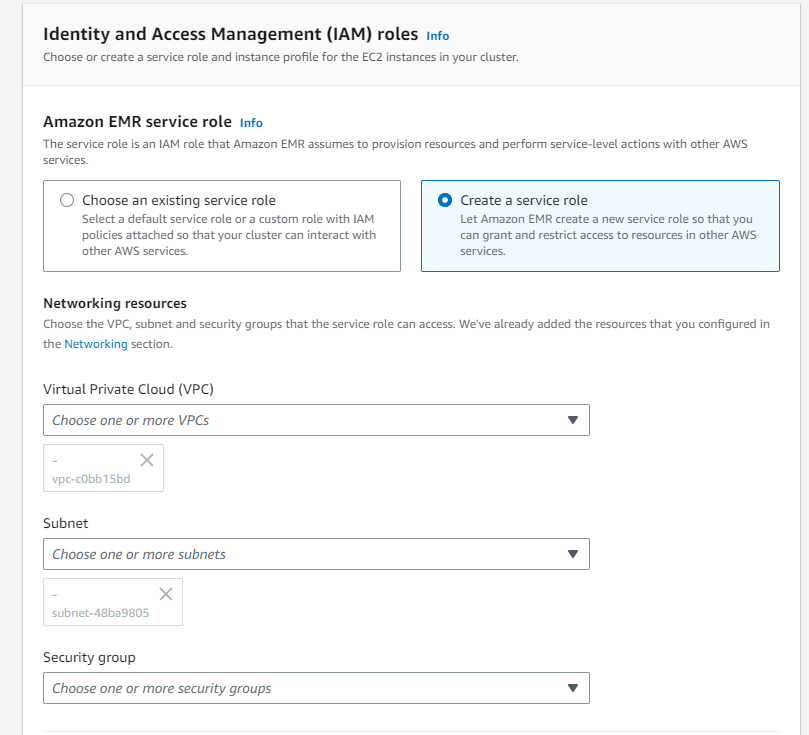
- Identity and Access Management (IAM) roles
- Amazon EMR service role: Create a service role
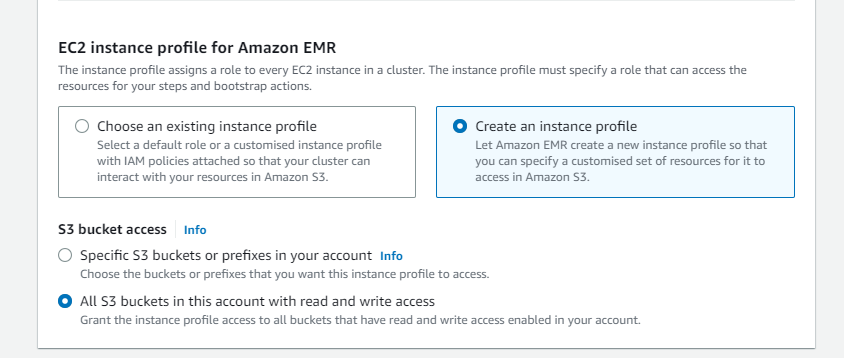
- EC2 instance profile for Amazon EMR: Create an instance profile
- S3 bucket access: All S3 buckets in this account with read and write access
- Click Create cluster
- Kiểm tra trạng thái của job Transform Job chạy trên EMR. EMR Cluster sẽ mất từ 6-8 phút để được chuẩn bị, và một phút nữa để hoàn thành thực thi bước Spark.
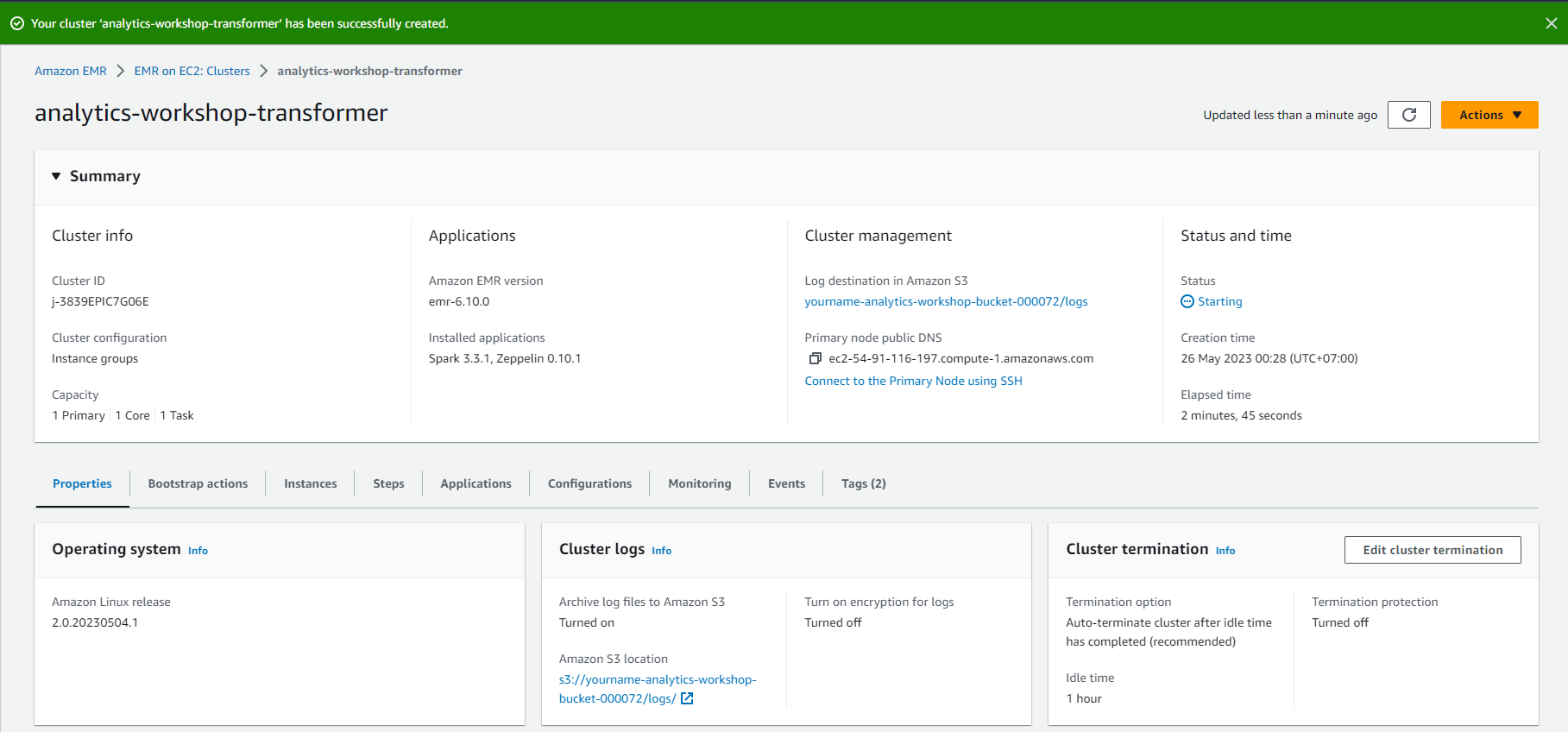
- Cluster sẽ bị chấm dứt sau khi job Spark được thực thi.
- Để kiểm tra trạng thái của job, Chọn vào tên EMR Cluster: analytics-workshop-transformer
- Chuyển đến tab Steps
- Ở đây bạn nên thấy hai mục: Spark application và Setup hadoop debugging
- Trạng thái của Spark application nên thay đổi từ Pending to Running to Completed.
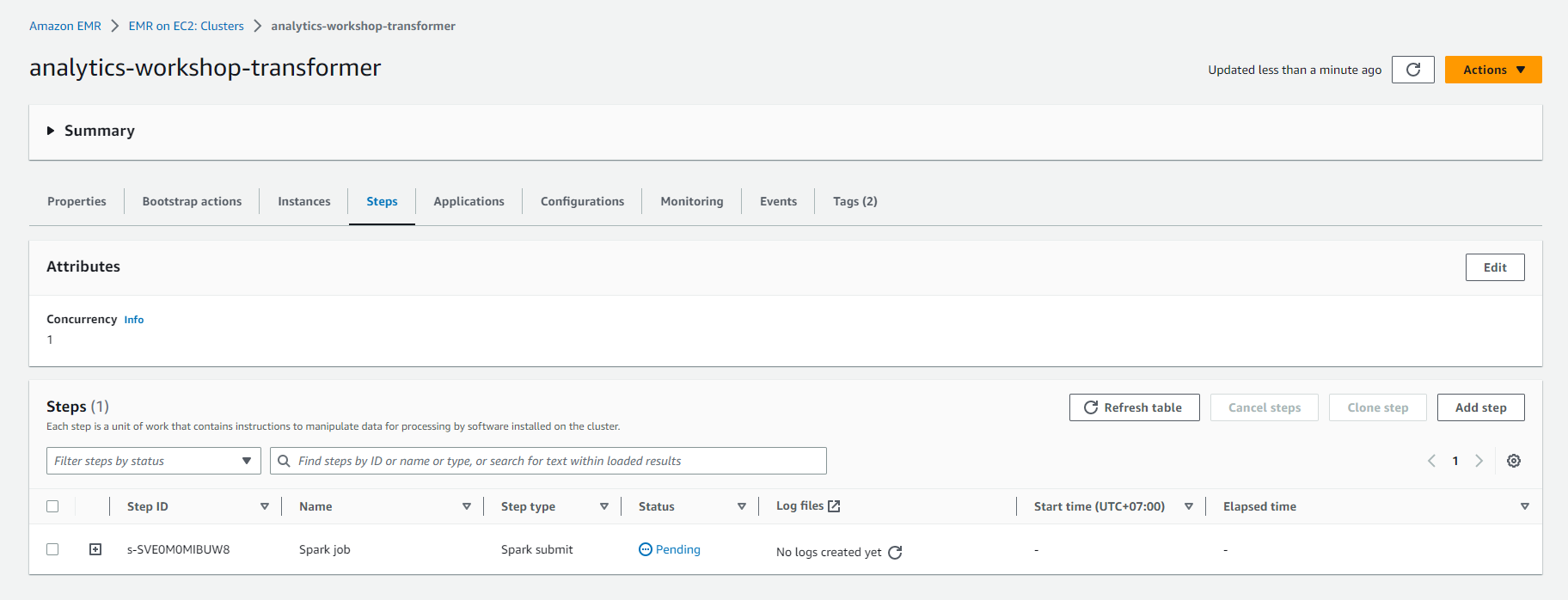
- Sau khi job chạy Spark hoàn tất, cụm EMR sẽ được chấm dứt.
- Dưới EMR > Cluster, bạn sẽ thấy Trạng thái của cụm là “Terminated” kèm theo thông báo “All steps completed”.

Validate - Dữ liệu đã được xác thực đã được gửi đến S3.
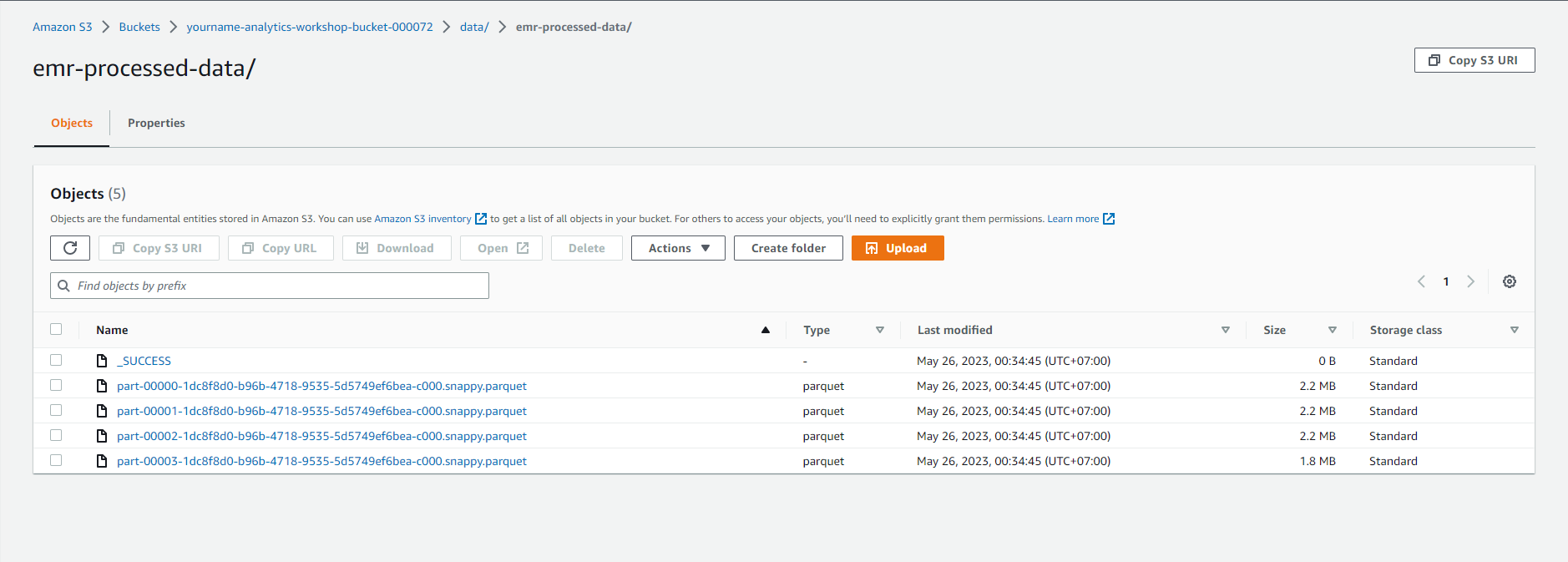
- Hãy tiến hành xác nhận rằng job chuyển đổi EMR đã tạo ra tập dữ liệu trong bảng điều khiển S3: Chọn vào đây
- Chọn vào - yourname-analytics-workshop-bucket > data
- Mở thư mục mới emr-processed-data:
- Đảm bảo rằng các tệp .parquet đã được tạo ra trong thư mục này.
Chạy lại Glue Crawler
- Đi tới: Bảng điều khiển Glue
- Trên bảng điều khiển bên trái, Chọn vào Crawlers (Công cụ thu thập dữ liệu)
- Chọn công cụ thu thập dữ liệu đã tạo trong module trước: AnalyticsworkshopCrawler
- Chọn vào Chạy (Run)
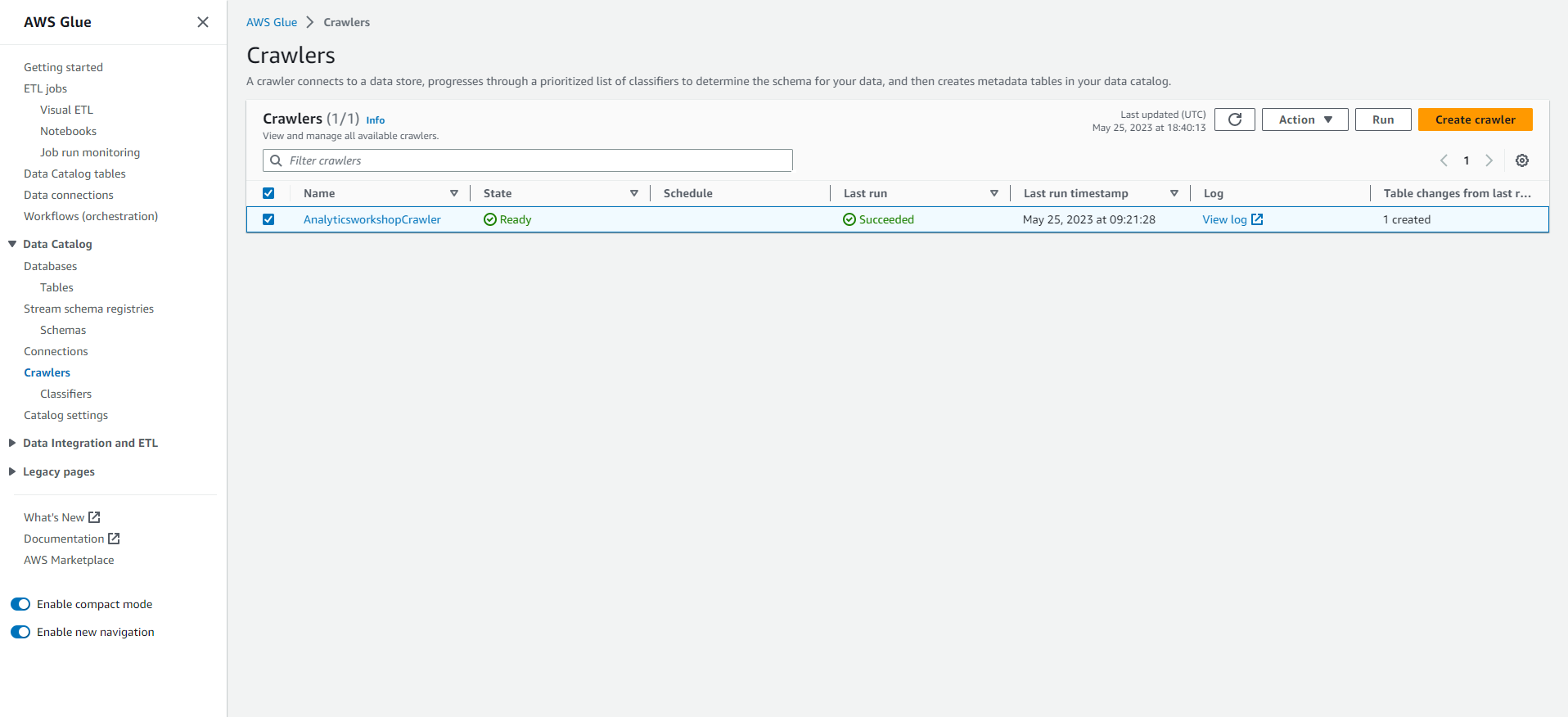
- Bạn sẽ thấy Trạng thái thay đổi thành Starting.
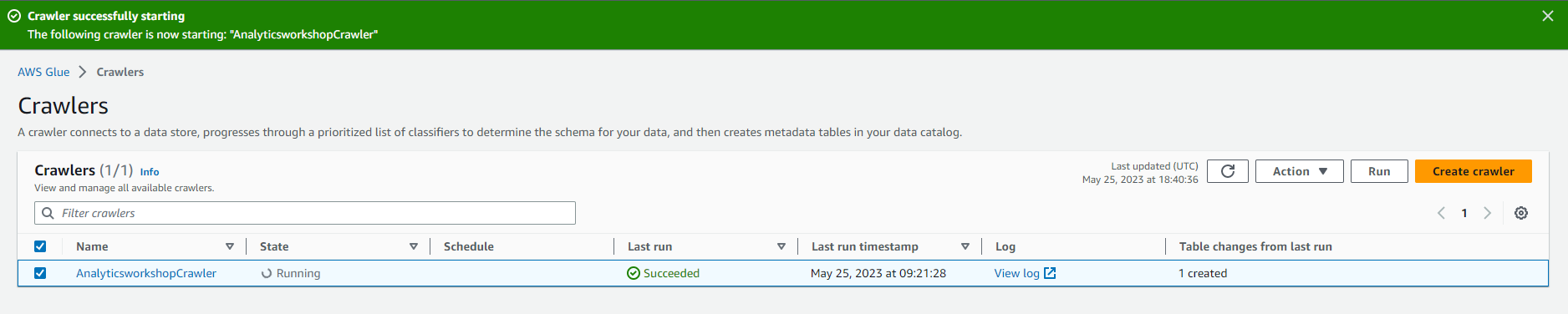
- Chờ vài phút cho quá trình chạy công cụ thu thập dữ liệu hoàn tất Công cụ thu thập dữ liệu sẽ hiển thị Các bảng được thêm là 1
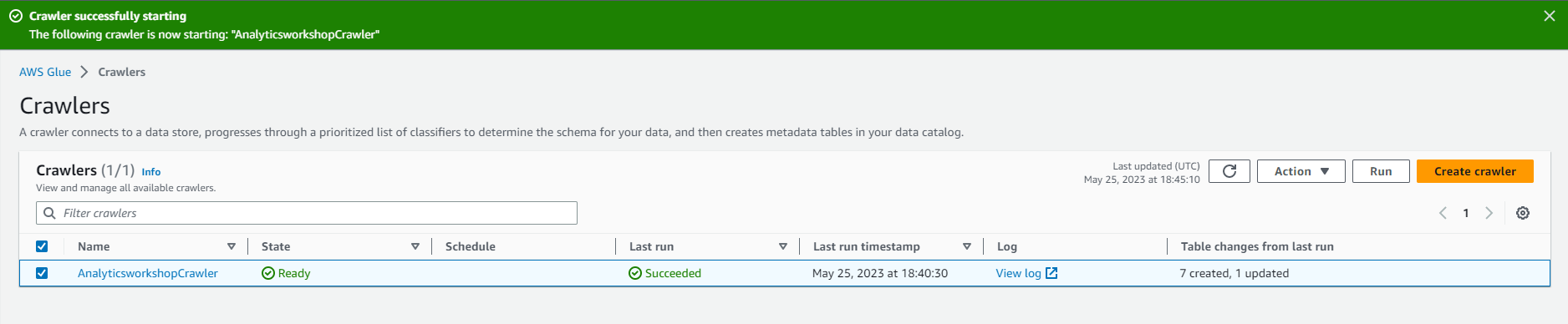
- Bạn có thể đi đến phần cơ sở dữ liệu ở bên trái và xác nhận rằng bảng emr_processed_data đã được thêm vào.
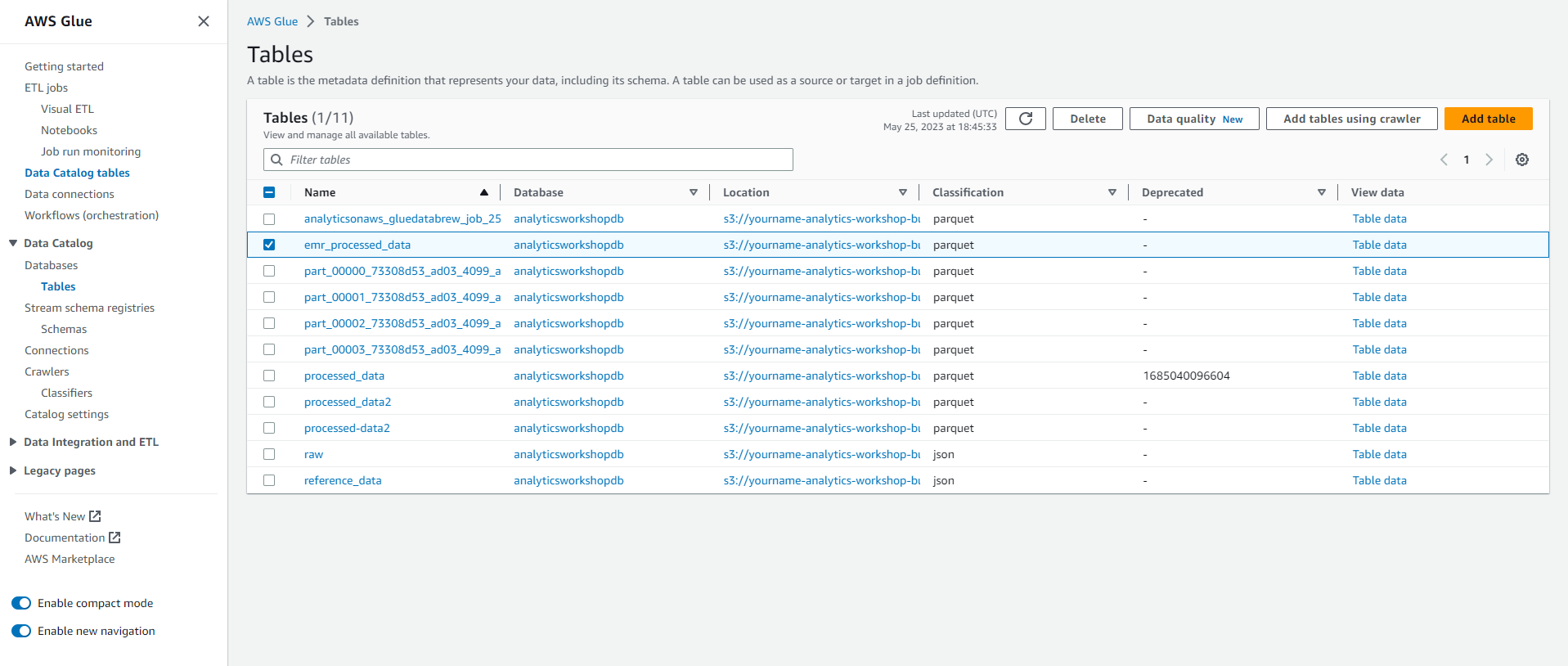
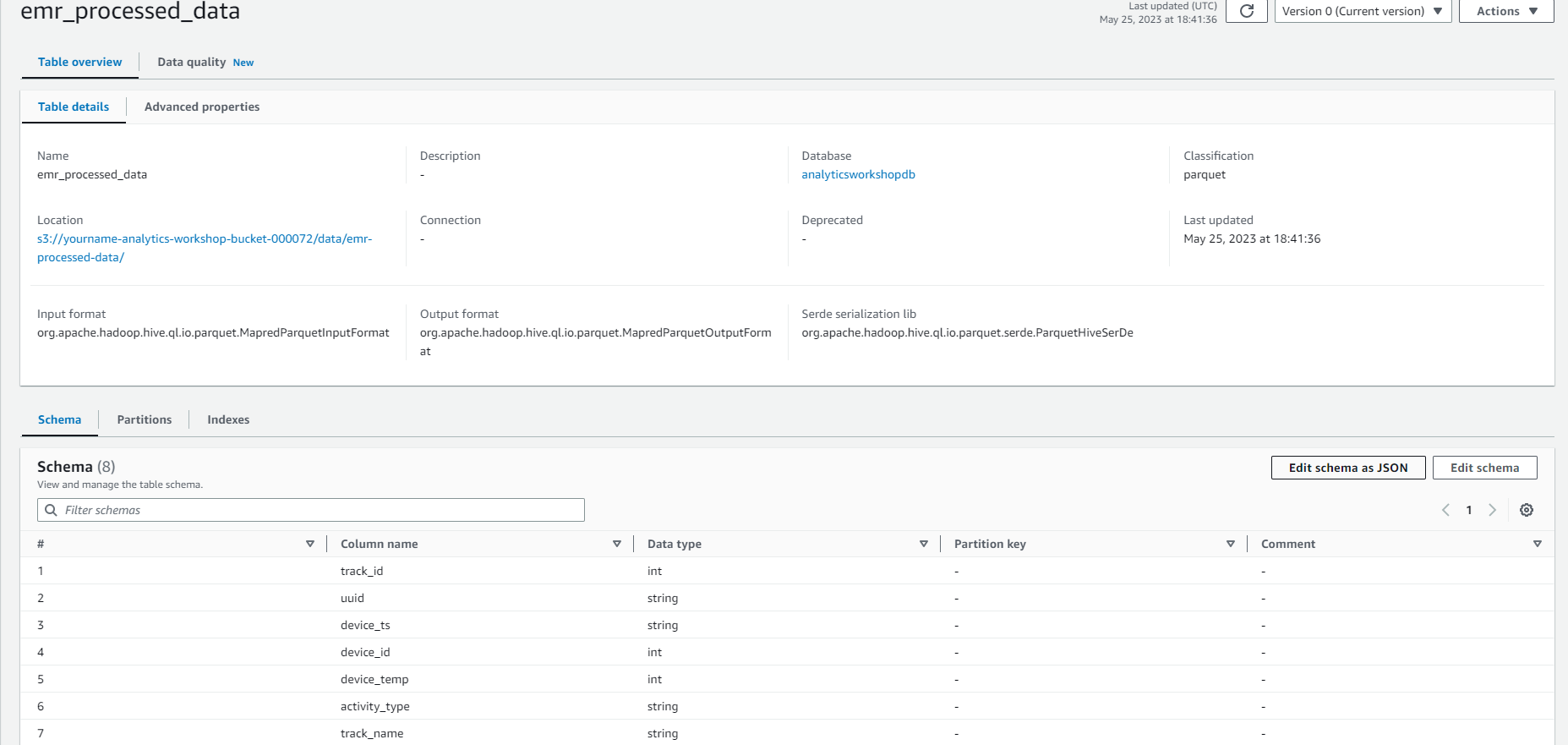
Bây giờ bạn có thể truy vấn kết quả của job EMR bằng cách sử dụng Amazon Athena trong module Next.