Warehouse trên Redshift
Warehouse trên Redshift
Trong module này, chúng ta sẽ thiết lập một Amazon Redshift cluster và sử dụng AWS Glue để tải dữ liệu vào Amazon Redshift. Chúng ta sẽ tìm hiểu về một số yếu tố thiết kế và các best practice trong việc tạo và tải dữ liệu vào các bảng trong Redshift, cũng như thực hiện các truy vấn trên nó.
- Chuẩn bị các Glue IAM policies và role
-
Chú ý: Bỏ qua phần này nếu bạn đã tạo Glue IAM policies và role trong mô-đun “Chuyển đổi dữ liệu với AWS Glue (phiên tương tác)” và tiếp tục đến phần “Tạo IAM role cho Redshift” trong mô-đun này.
-
Trong bước này, bạn sẽ truy cập vào bảng điều khiển IAM và tạo các Glue IAM policies và role để làm việc với các Jupyter notebooks và phiên tương tác của AWS Glue Studio.
-
Hãy bắt đầu bằng việc tạo một policy IAM cho AWS Glue notebook role .
-
Chọn vào Policies từ bảng điều khiển trên thanh bên trái
-
Chọn vào Create policy
-
Chọn vào tab JSON
-
Thay thế văn bản mặc định trong cửa sổ chỉnh sửa policy bằng các câu lệnh policy sau đây.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource":"arn:aws:iam::<AWS account ID>:role/Analyticsworkshop-GlueISRole"
}
]
}
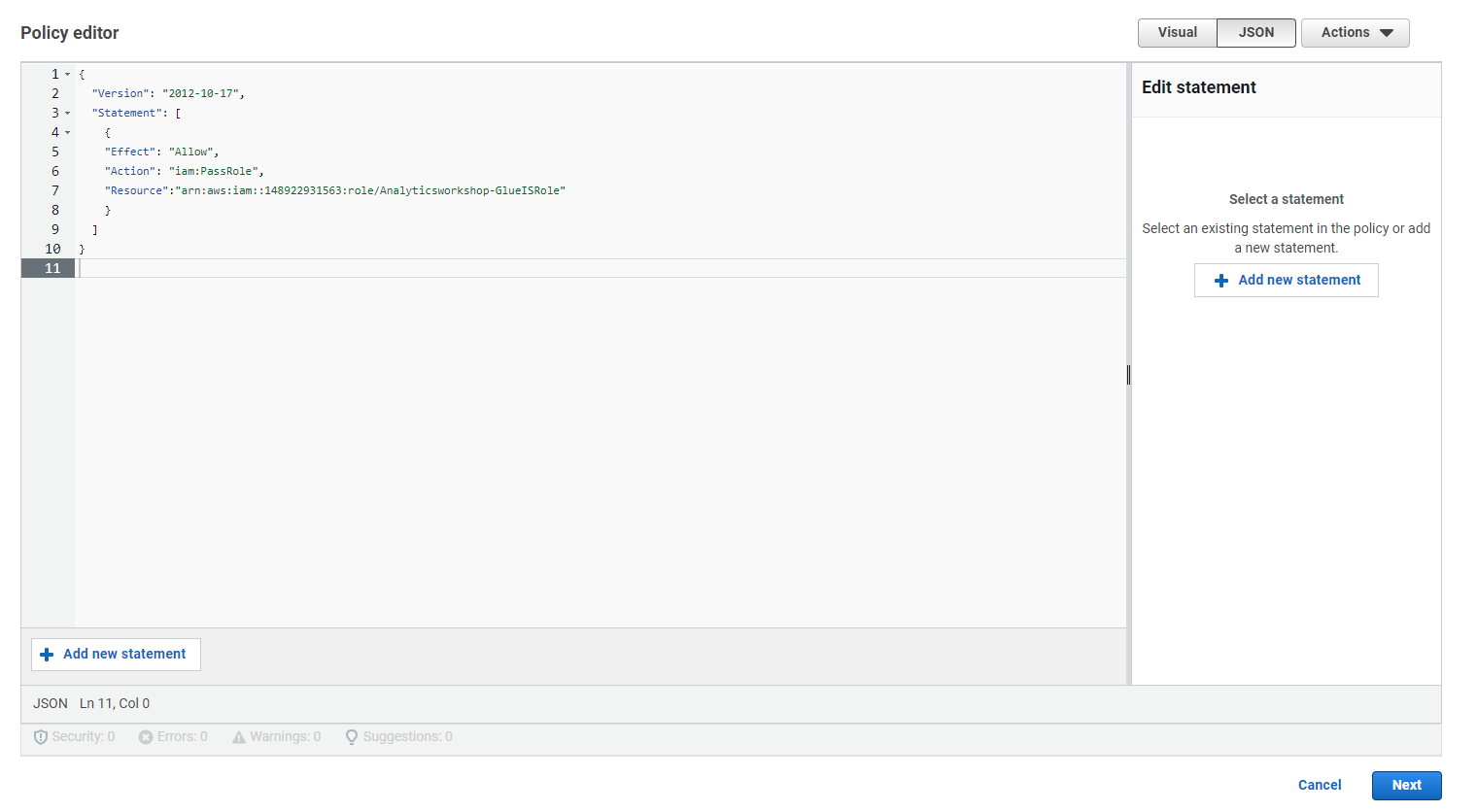
- Lưu ý rằng Analyticsworkshop-GlueISRole là role chúng ta tạo cho Jupyter notebook của AWS Glue Studio trong bước Next.
-
Cảnh báo: Thay thế bằng ID tài khoản AWS của bạn trong câu lệnh policy đã sao chép.
-
Chọn vào Next: Tags
-
Tùy chọn thêm các Tag, ví dụ: workshop: AnalyticsOnAWS
-
Chọn vào Next: Review
-
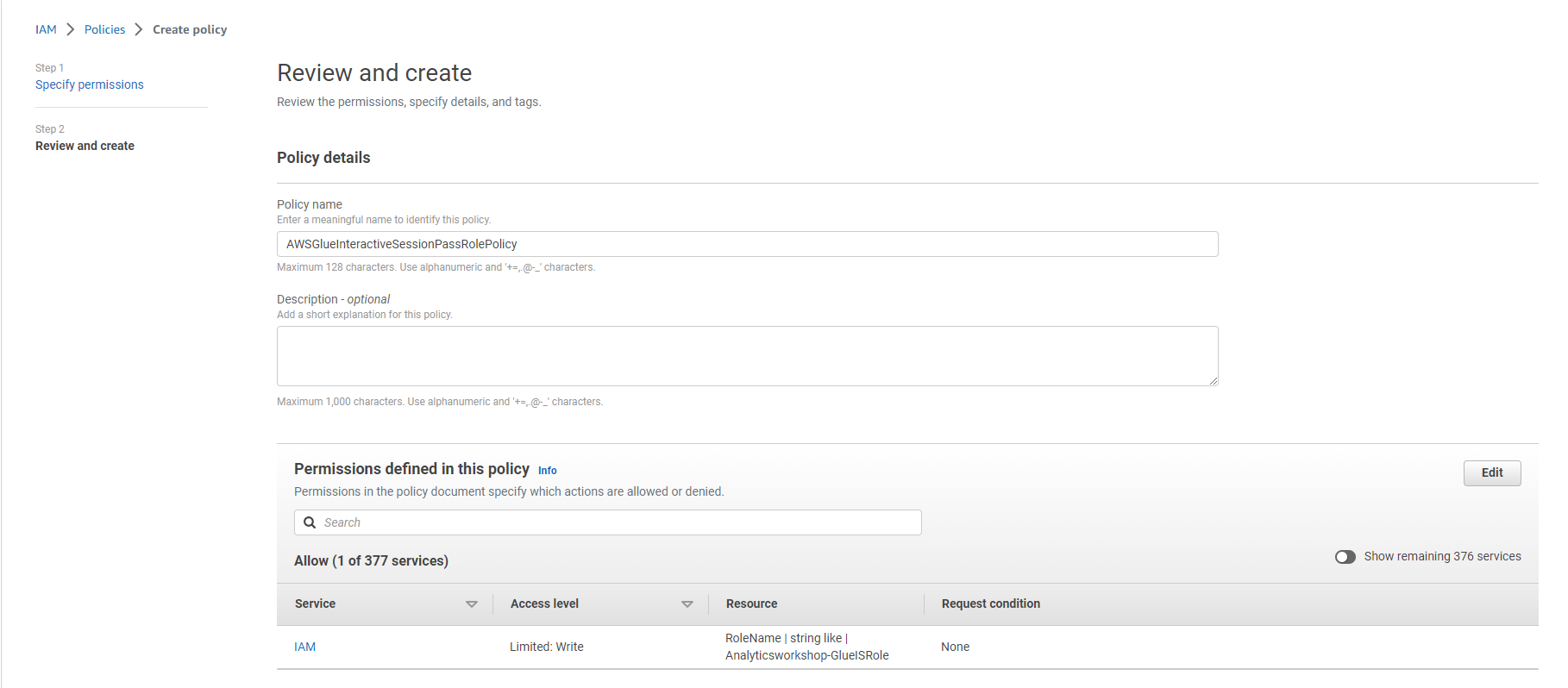
Tên policy: AWSGlueInteractiveSessionPassRolePolicy
-
Tùy chọn viết mô tả cho policy:
-
Description: policy cho phép role của sổ ghi chú AWS Glue chuyển cho các phiên tương tác để cùng một role có thể được sử dụng ở cả hai nơi
-
Chọn vào Create policy

- Next, tạo một role IAM cho sổ ghi chú AWS Glue
- Chọn vào Roles từ bảng điều khiển trái
- Chọn vào Create role
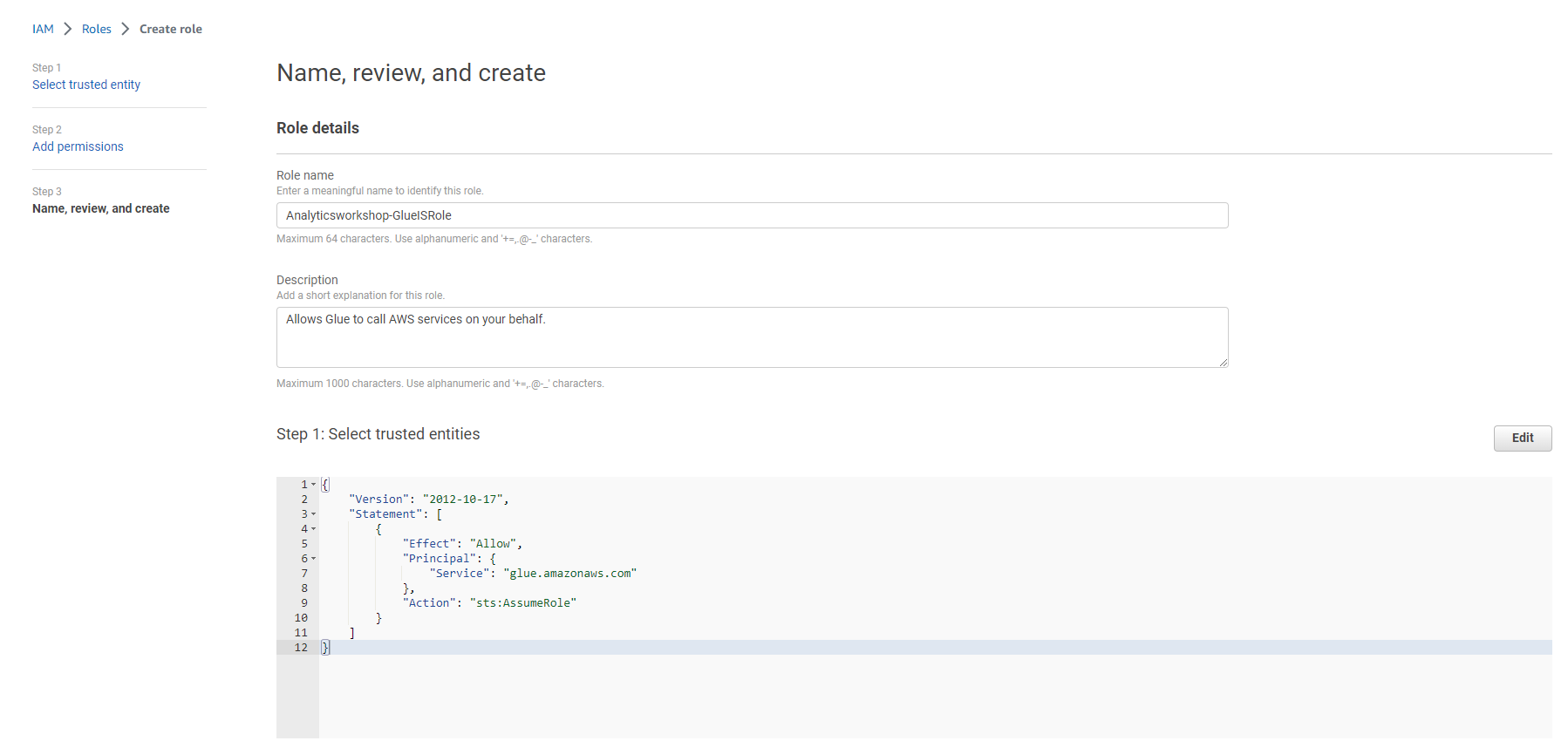
- Chọn dịch vụ sẽ sử dụng role này: Glue dưới Use Case và Use cases for other AWS services:
- Chọn vào Next
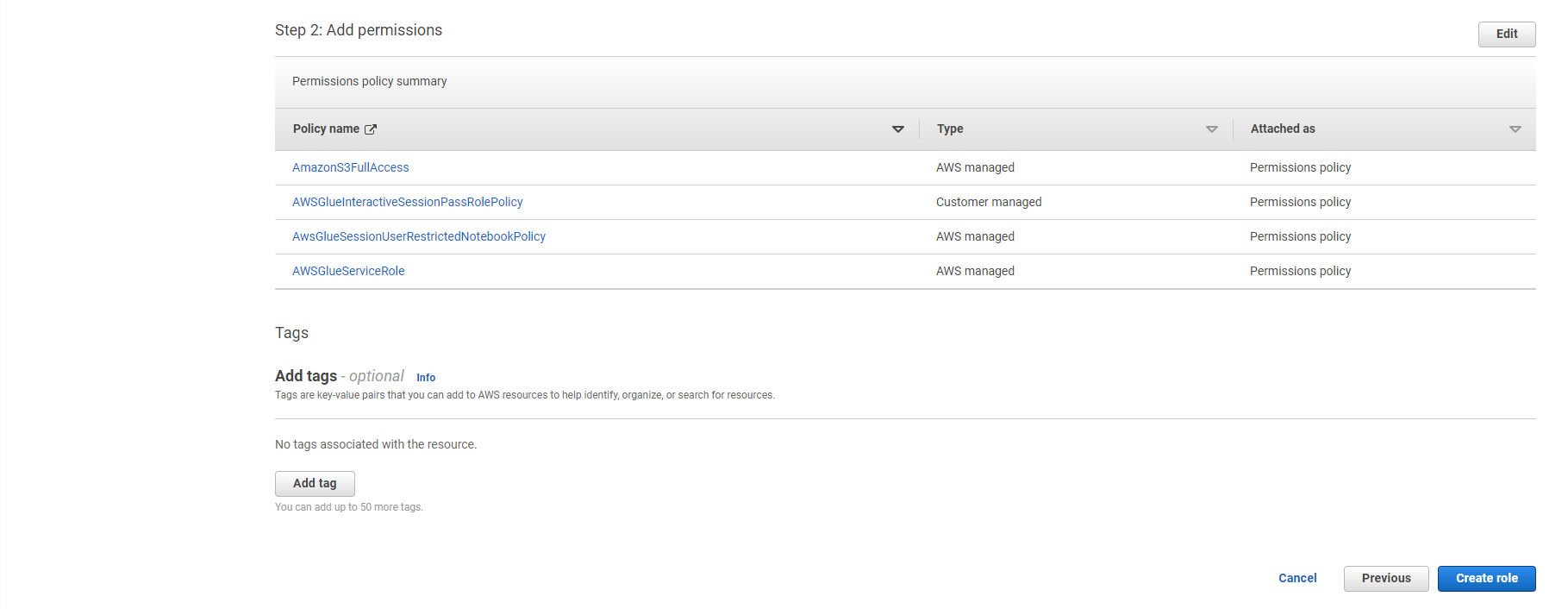
- Tìm kiếm các policy sau và chọn hộp đánh dấu bên cạnh chúng:
- AWSGlueServiceRole
- AwsGlueSessionUserRestrictedNotebookPolicy
- AWSGlueInteractiveSessionPassRolePolicy
- AmazonS3FullAccess
- Chọn vào Next

- Tên role: Analyticsworkshop-GlueISRole
- Đảm bảo chỉ có bốn policy được gắn kết vào role này (AWSGlueServiceRole, AwsGlueSessionUserRestrictedNotebookPolicy, AWSGlueInteractiveSessionPassRolePolicy, AmazonS3FullAccess)
- Tùy chọn thêm Tag, ví dụ: workshop: AnalyticsOnAWS
- Chọn vào Create role
- Lưu ý: Chúng tôi đã cấp quyền truy cập đầy đủ vào S3 cho role Glue cho mục đích của buổi thực hành này. Đề nghị chỉ cấp quyền cho phép cần thiết để thực hiện một nhiệm vụ, tức là tuân thủ mô hình quyền hạn ít nhất có thể trong triển khai thực tế.
- Tạo IAM role cho Redshift
- Trong bước này, chúng ta sẽ tạo một IAM role cho cụm Redshift.
- Đi đến: Bảng điều khiển Redshift
- Chọn vào Create Role
- Chọn Redshift dưới Use case và Use cases for other AWS services:
- Chọn Redshift - customizable
- Chọn Next
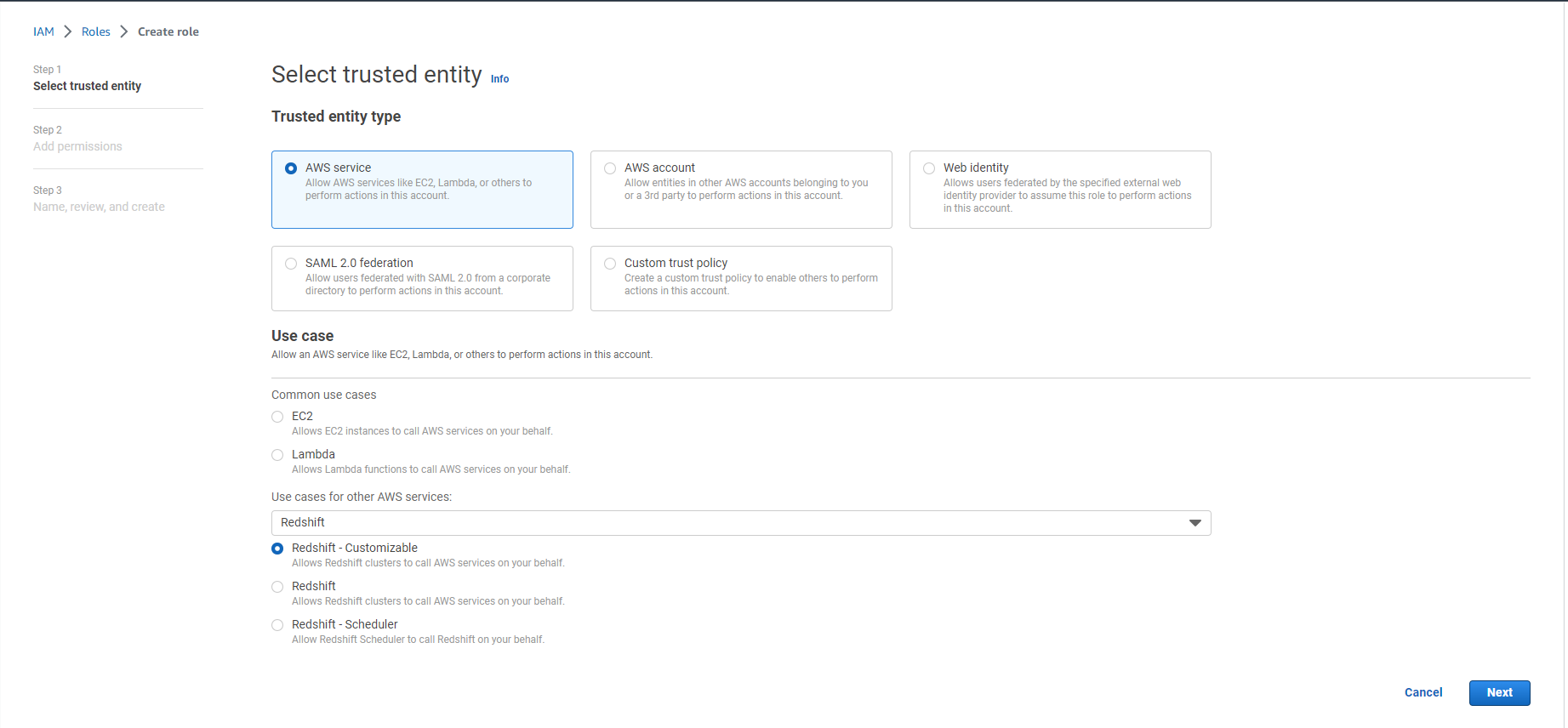
- Trong ô Tìm kiếm, tìm kiếm và chọn hai policy sau
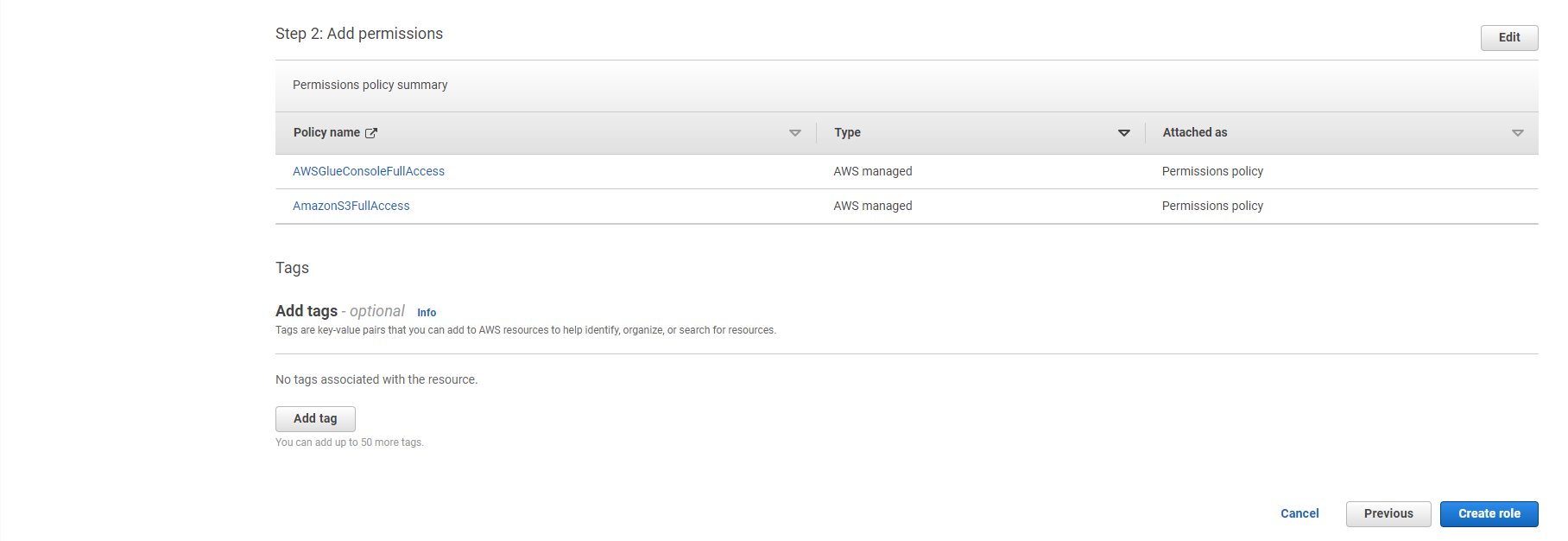
- AmazonS3FullAccess
- AWSGlueConsoleFullAccess
- Chọn Next
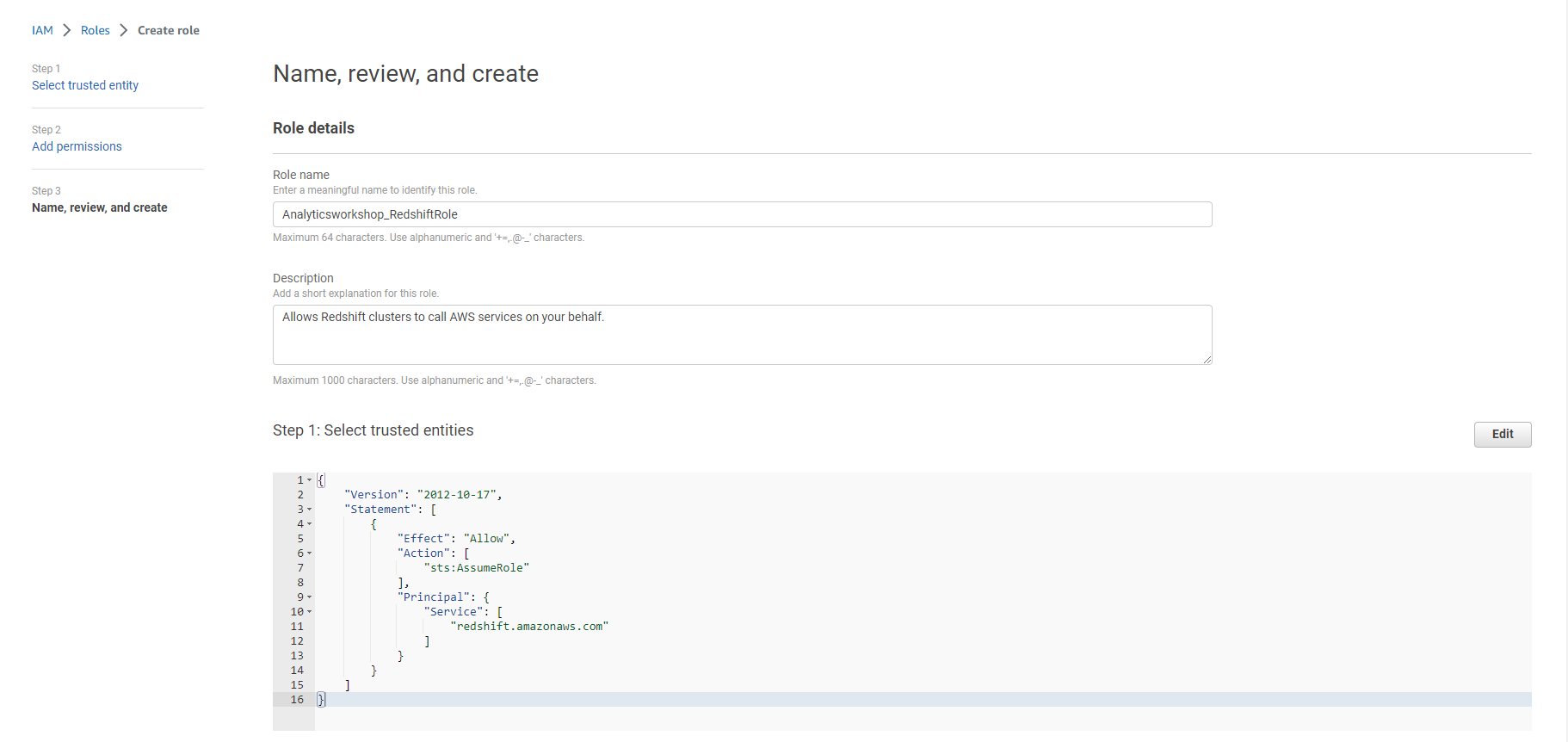
- Đặt Role name là Analyticsworkshop_RedshiftRole
- Xác minh rằng hai policy sau được gắn vào role:
- AmazonS3FullAccess
- AWSGlueConsoleFullAccess
- Tùy chọn thêm Tags, ví dụ: workshop: AnalyticsOnAWS
- Chọn Create Role
Tạo Redshift cluster
- Trong bước này, bạn sẽ tạo một Redshift cluster gồm 2 node để tạo cơ sở dữ liệu mini theo mô hình sao.
- Truy cập vào: Console
- Chọn vào Provision and manage clusters từ bảng điều khiển trên cùng bên trái
- Chọn vào Create Cluster
- Giữ nguyên Cluster identifier là redshift-cluster-1
- Chọn dc2.large làm Node Type
- Chọn Number of Nodes là 2.
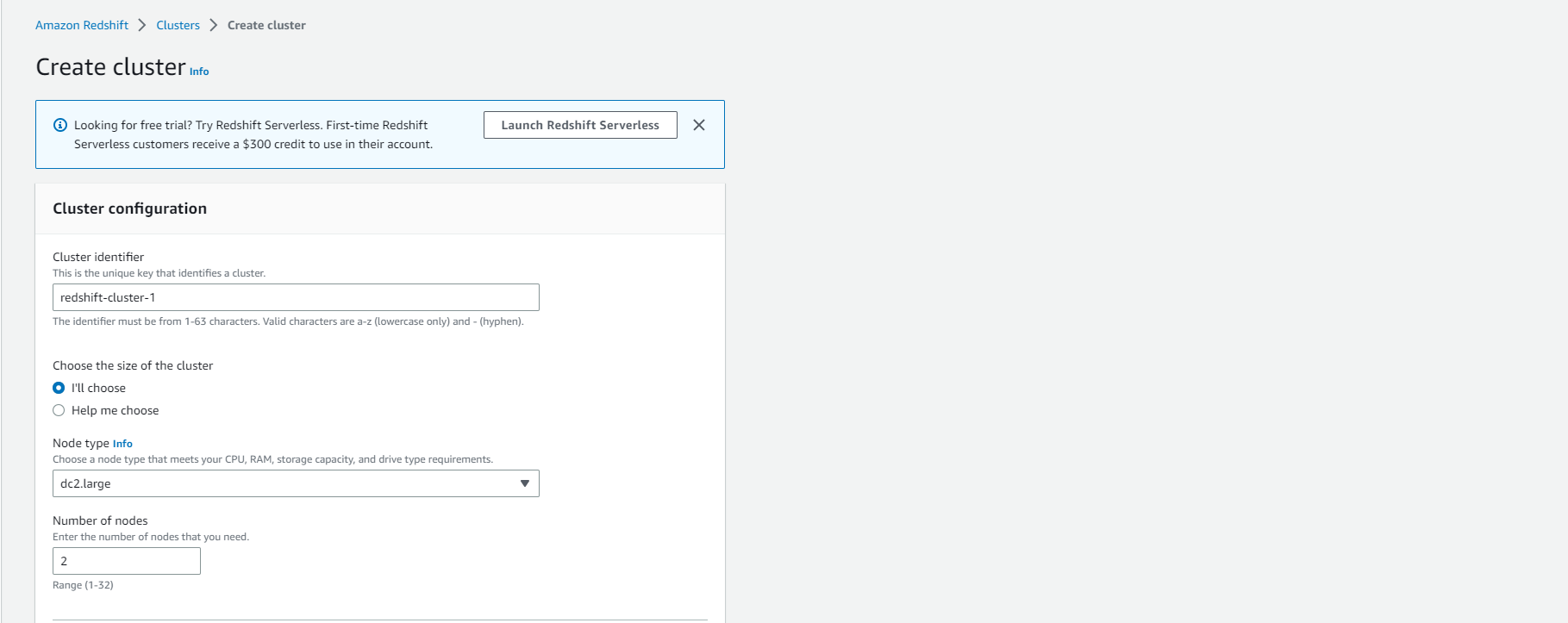
- Xác nhận Configuration summary.
- Thay đổi Master user name thành admin
- Nhập Master user password.
- Kiểm tra các quy tắc mật khẩu được đề cập dưới Master user password trước khi chọn một mật khẩu. (Mật khẩu này sẽ được sử dụng để truy cập vào cụm)
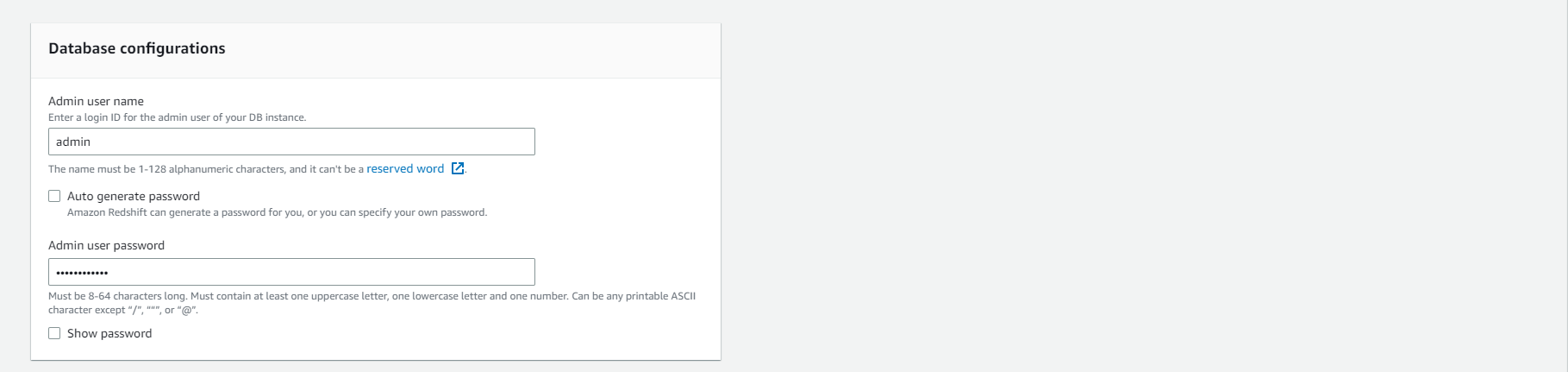
- Dưới Cluster permissions
- Chọn vào Associate IAM role
- Chọn Analyticsworkshop_RedshiftRole đã được tạo trước đó.
- Chọn vào Associate IAM roles
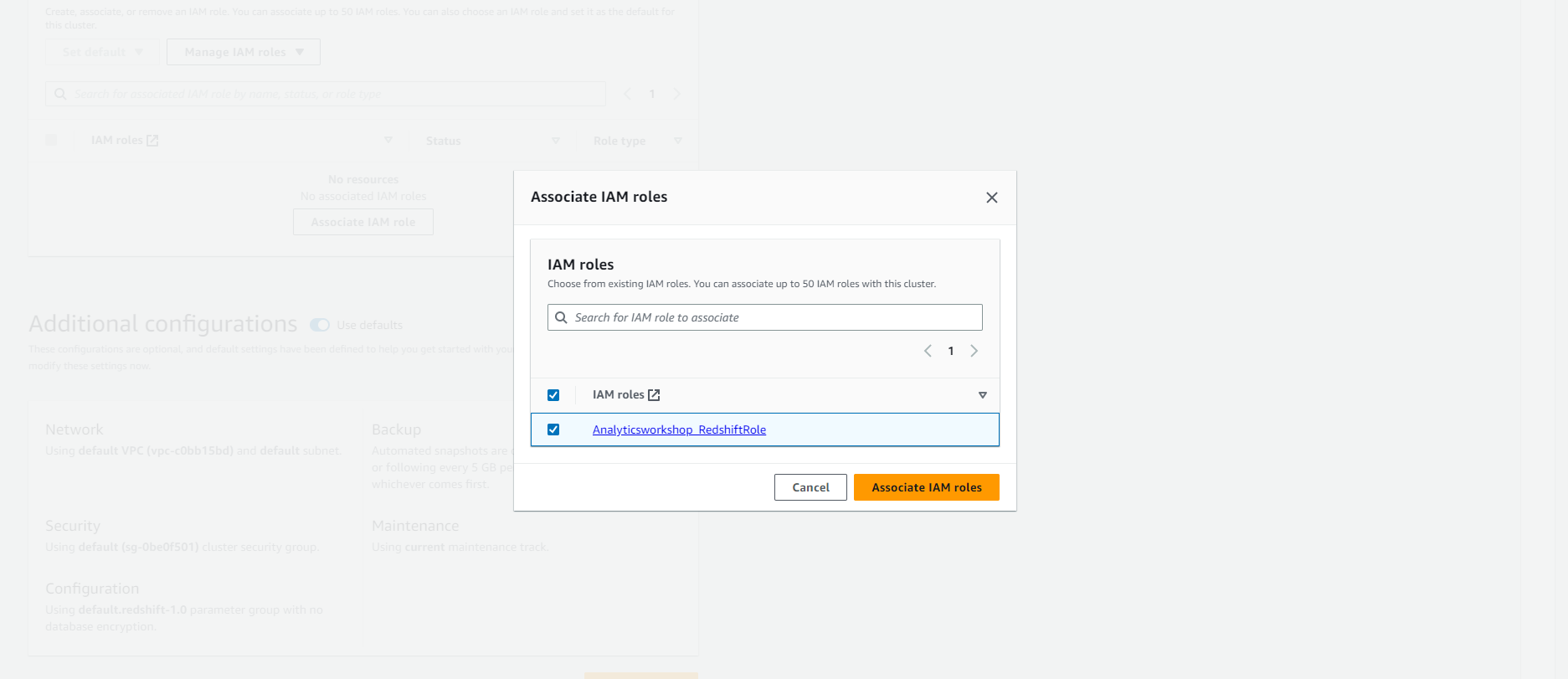
- Analyticsworkshop_RedshiftRole sẽ xuất hiện dưới Associated IAM roles
- Giữ nguyên Additional configurations theo mặc định. Nó sử dụng VPC mặc định và nhóm bảo mật mặc định.
- Chọn vào Create cluster
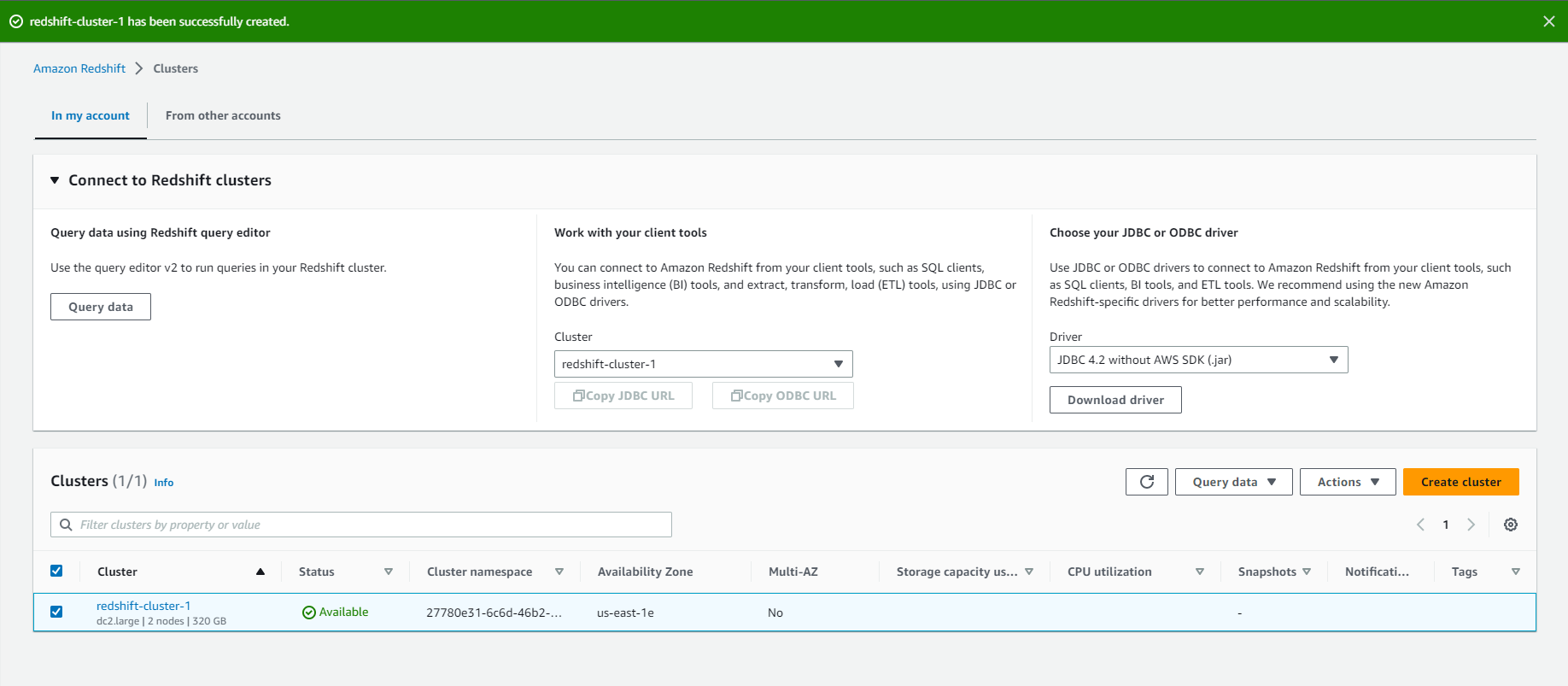
- Mất vài phút để cụm chuyển sang trạng thái available.
- Sau khi cụm đã được khởi động và ở trạng thái Available, chuyển sang bước Next.
Tạo S3 Gateway Endpoint
- Trong bước này, chúng ta sẽ tạo S3 Gateway Endpoint để Redshift cluster có thể giao tiếp với S3 bằng cách sử dụng địa chỉ IP riêng.
- Truy cập: Bảng điều khiển AWS VPC
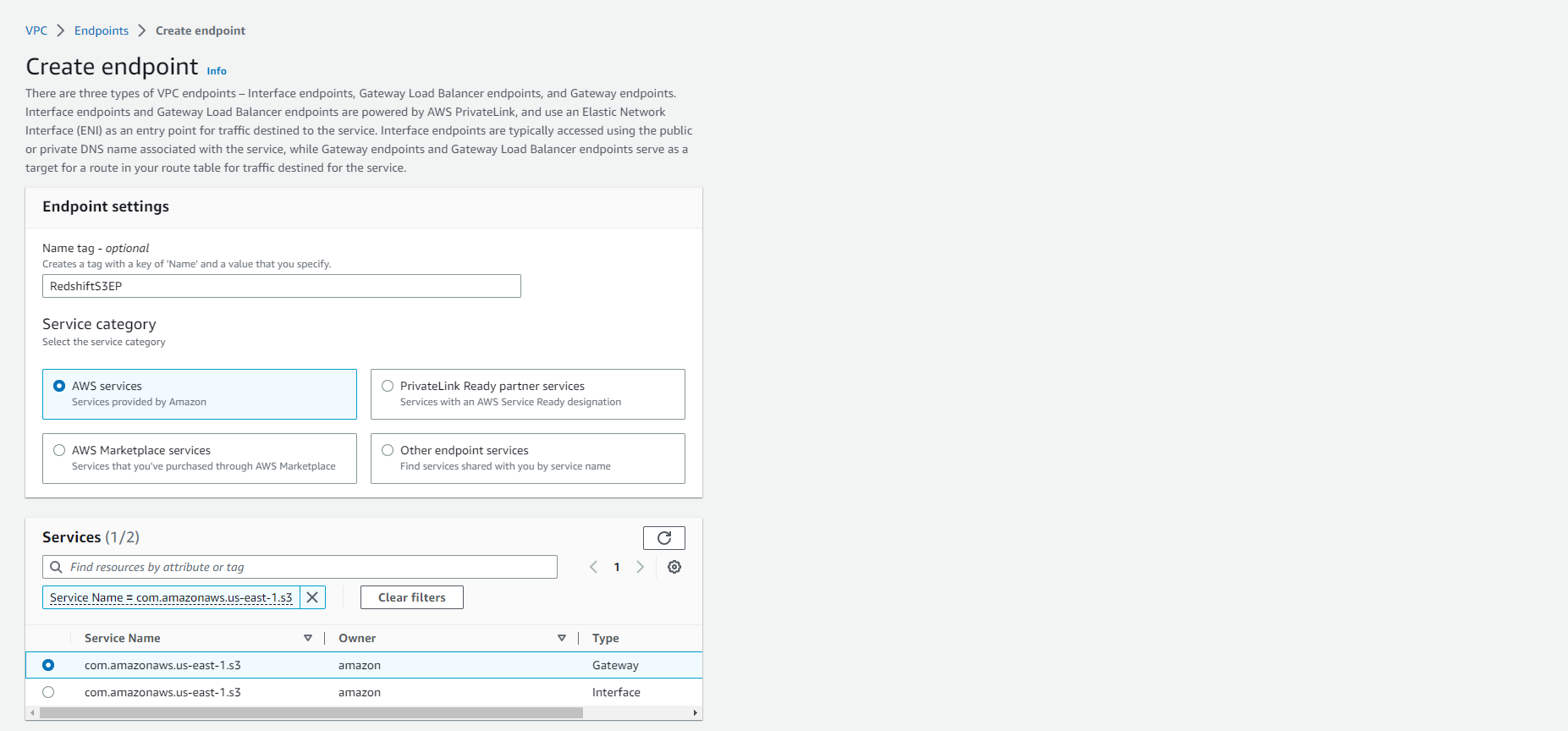
- Chọn vào Create endpoint

- Name tag - optional: RedshiftS3EP
- Chọn AWS Services trong Service category (đây là lựa chọn mặc định)
- Trong ô tìm kiếm Service name, tìm kiếm “s3” và Chọn Enter/Return.
- com.amazonaws.us-east-1.s3 sẽ xuất hiện như kết quả tìm kiếm. Chọn tùy chọn này với loại là Gateway.
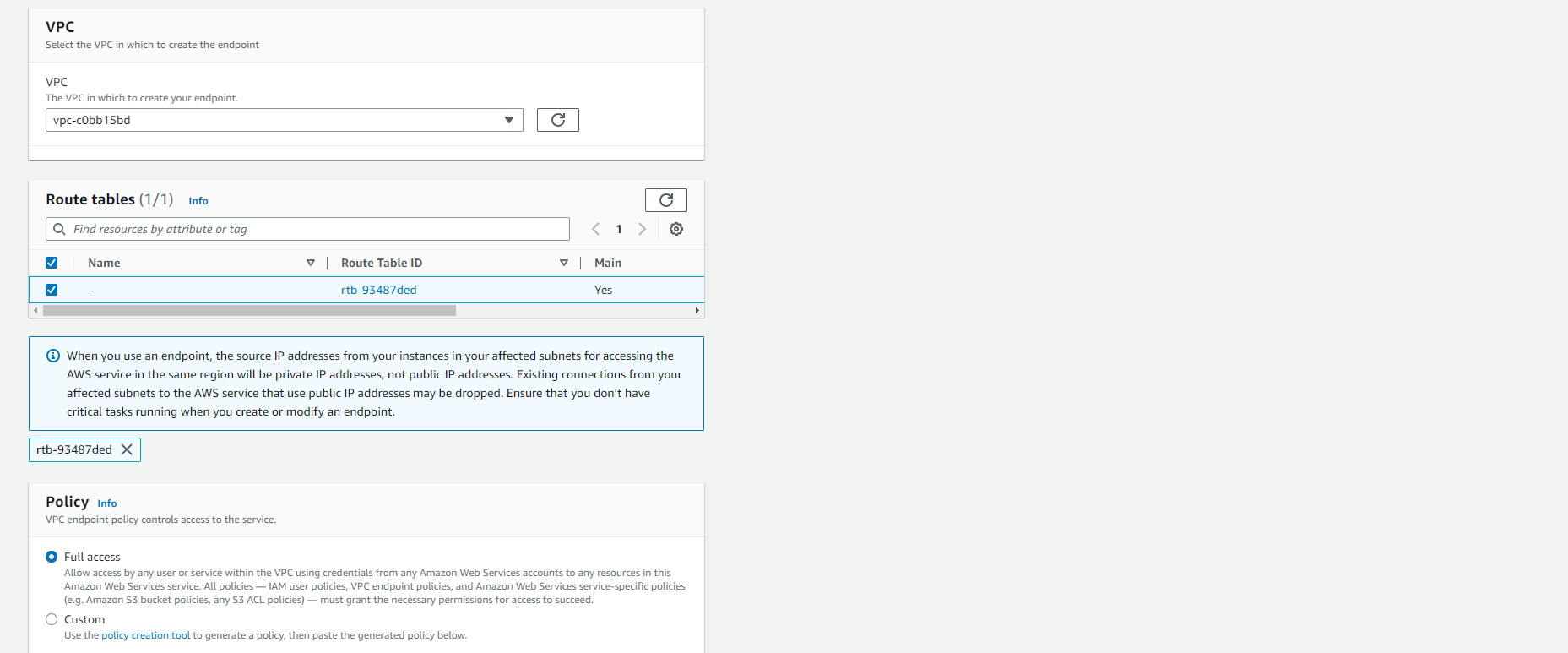
- Chọn VPC, chọn VPC mặc định. Đây là cùng VPC đã được sử dụng để cấu hình redshift cluster.
- Nếu có nhiều hơn một VPC được liệt kê trong danh sách thả xuống, hãy kiểm tra lại VPC của Redshift để tránh hiểu nhầm. Thực hiện các bước sau:
- Truy cập: Bảng điều khiển Redshift
- Chọn vào redshift-cluster-1
- Chọn vào Properties tab.
- Cuộn xuống và kiểm tra phần Network and security để tìm tên VPC.
- Sau khi kiểm tra lại ID VPC, tiếp tục cấu hình phần Route tables.
- Chọn bảng định tuyến được liệt kê (đây nên là bảng định tuyến chính). Bạn có thể xác minh điều này bằng cách kiểm tra Yes trong cột Chính.
- Giữ mặc định cho Policy. (Full access)
- Tùy chọn thêm các Tag, ví dụ: * workshop: AnalyticsOnAWS
- Chọn vào Create endpoint. Việc cung cấp điểm cuối này có thể mất một vài giây. Khi điểm cuối này đã sẵn sàng, bạn sẽ thấy Status là Available đối với điểm cuối S3 vừa tạo mới.

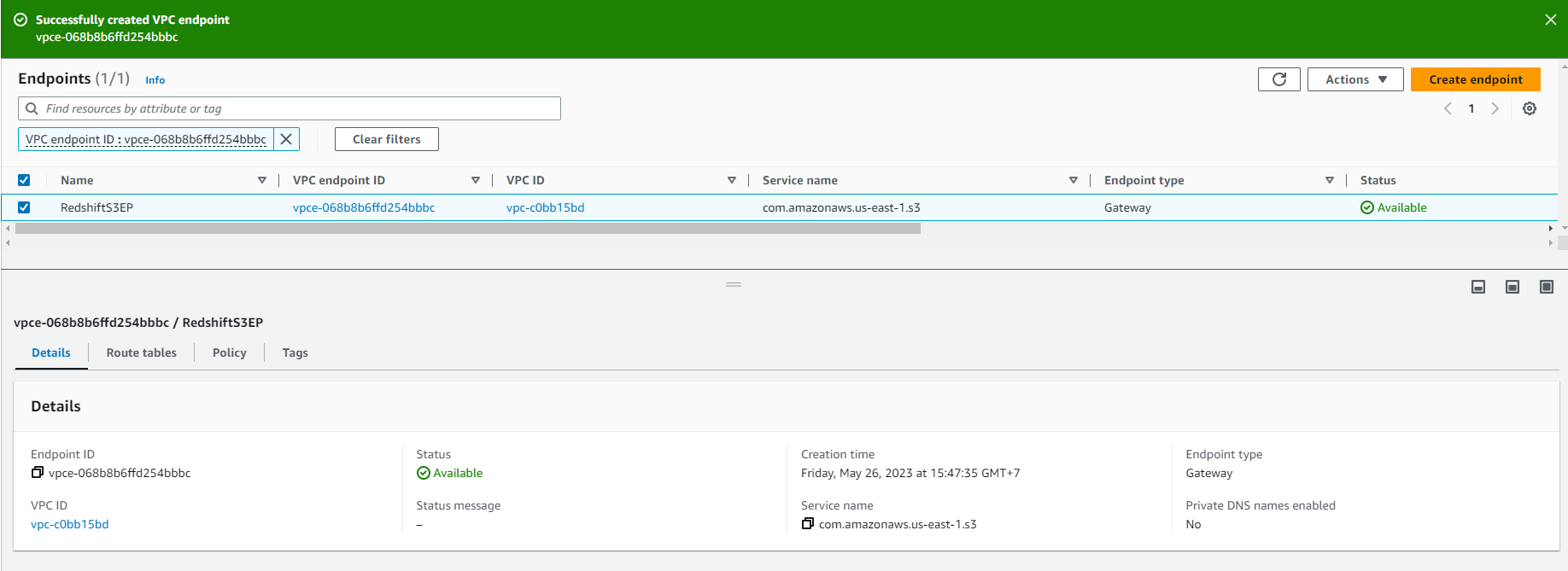
Xác minh và thêm các quy tắc vào security group mặc định
- Trong bước này, bạn sẽ xác minh và thêm các rule vào security group Redshift để dịch vụ Glue có thể trò chuyện với Redshift.
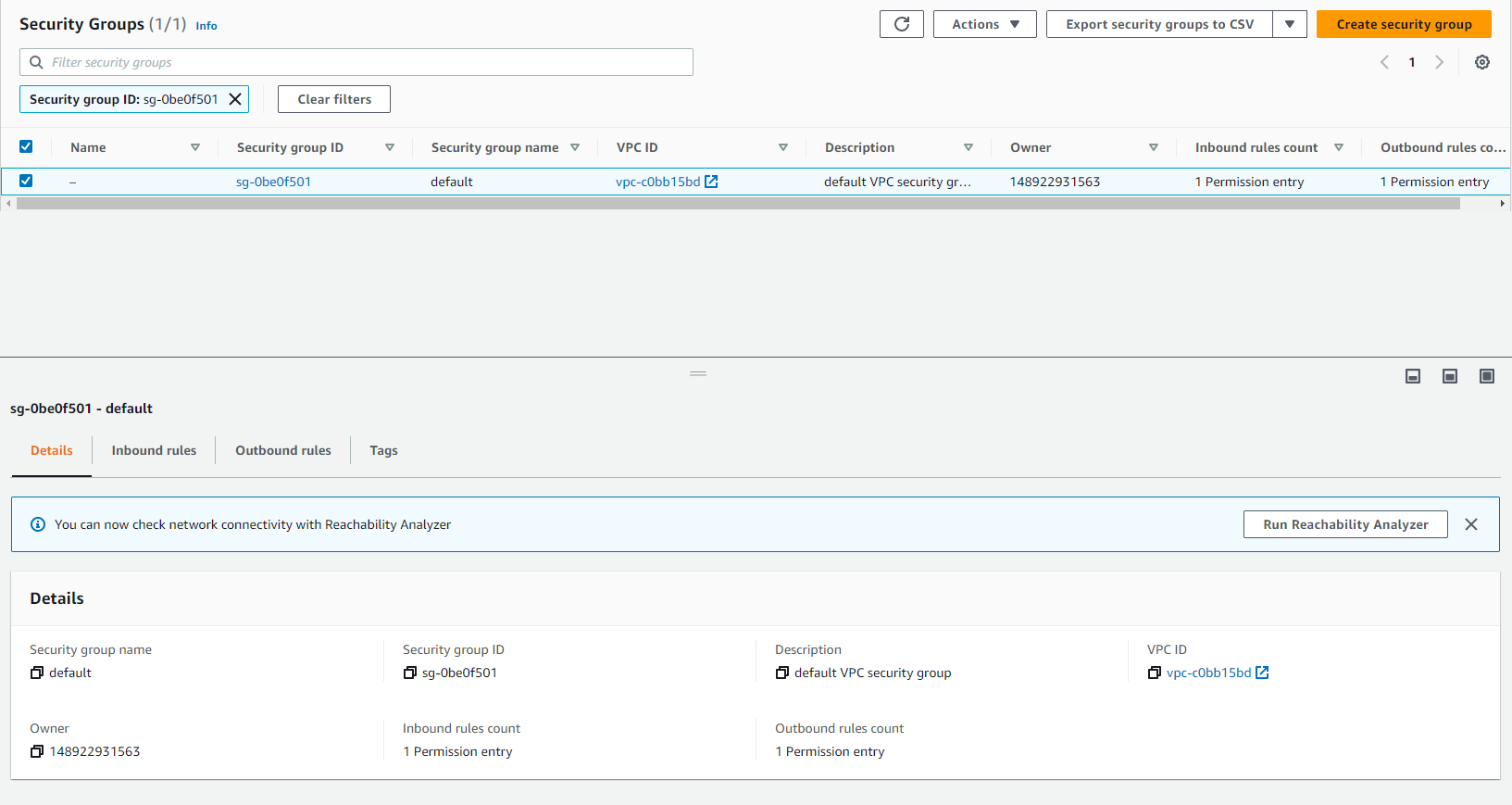
- Truy cập: Các security group VPC.
- Chọn security group Redshift. Nếu security group mặc định không được thay đổi trong quá trình tạo cụm Redshift, nó sẽ là security group mặc định.
- Nếu bạn có nhiều hơn một security group trong danh sách, làm theo các bước dưới đây:
- Truy cập: Bảng điều khiển Redshift.
- Chọn vào redshift-cluster-1
- Chọn vào Properties tab.
- Cuộn xuống và kiểm tra phần Network and security để tìm Security Group id.
- Sau khi đã xác minh Security Group, chọn Security Group (hộp kiểm ở đầu dòng).
- Chọn vào Inbound Rules.
- Chọn vào Edit inbound rules.
- Kiểm tra xem có rule trỏ đến chính mình hay không. (Quy tắc này nên có sẵn theo mặc định, nhưng nếu không có, hãy thêm quy tắc như được liệt kê dưới đây)
- Type: All Traffic
- Source: [Tên của security group cùng với security group bạn đang chỉnh sửa] Lưu ý: Quy tắc trỏ đến chính mình là cần thiết để các thành phần Glue giao tiếp.
- Add HTTPS rule for Amazon S3 access.
- Type: HTTPS
- Source: Custom
- Note : Under Source select Custom and type “pl”
- Click Save rules.
- Click Outbound Rules.
- Click Edit rules
- Type as “All Traffic”
- Add a self-referencing rule.
- Type: All TCP
- Source: [Name of the same security group which you are editing] Note : A self-referencing rule is required for Glue components to communicate.
- Click Save rules.
Tạo Redshift connection trong Glue Connection.
- Trong bước này, chúng ta sẽ tạo một Redshift connection trong Glue connection mà chúng ta có thể sử dụng trong Development Endpoint để thiết lập kết nối với Redshift.
- Truy cập vào: Bảng điều khiển Glue Connections
- Dưới Connections Click Create connection
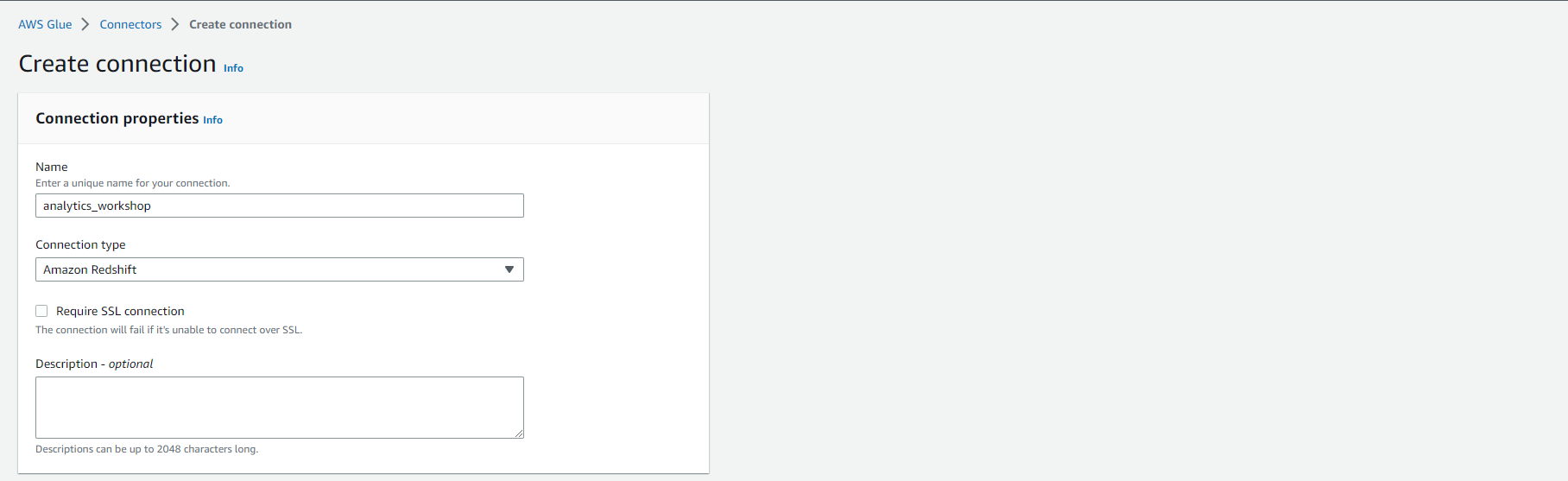
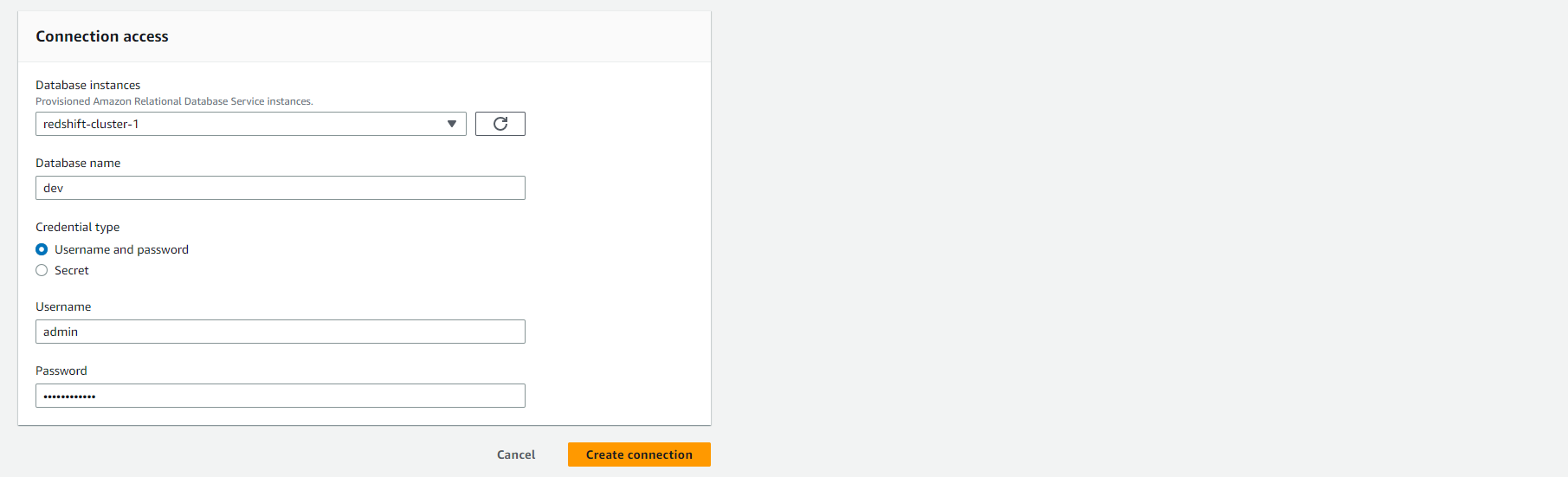
- Đặt connection name là analytics_workshop.
- Chọn onnection type là Amazon Redshift.
- Cài đặt quyền truy cập kết nối:
- Chọn Database instances là redshift-cluster-1
- Database name và Username sẽ tự động được điền vào là dev và admin tương ứng.
- Mật khẩu: Nhập mật khẩu mà bạn đã sử dụng trong quá trình cài đặt cụm Redshift.
- Chọn vào Create connection
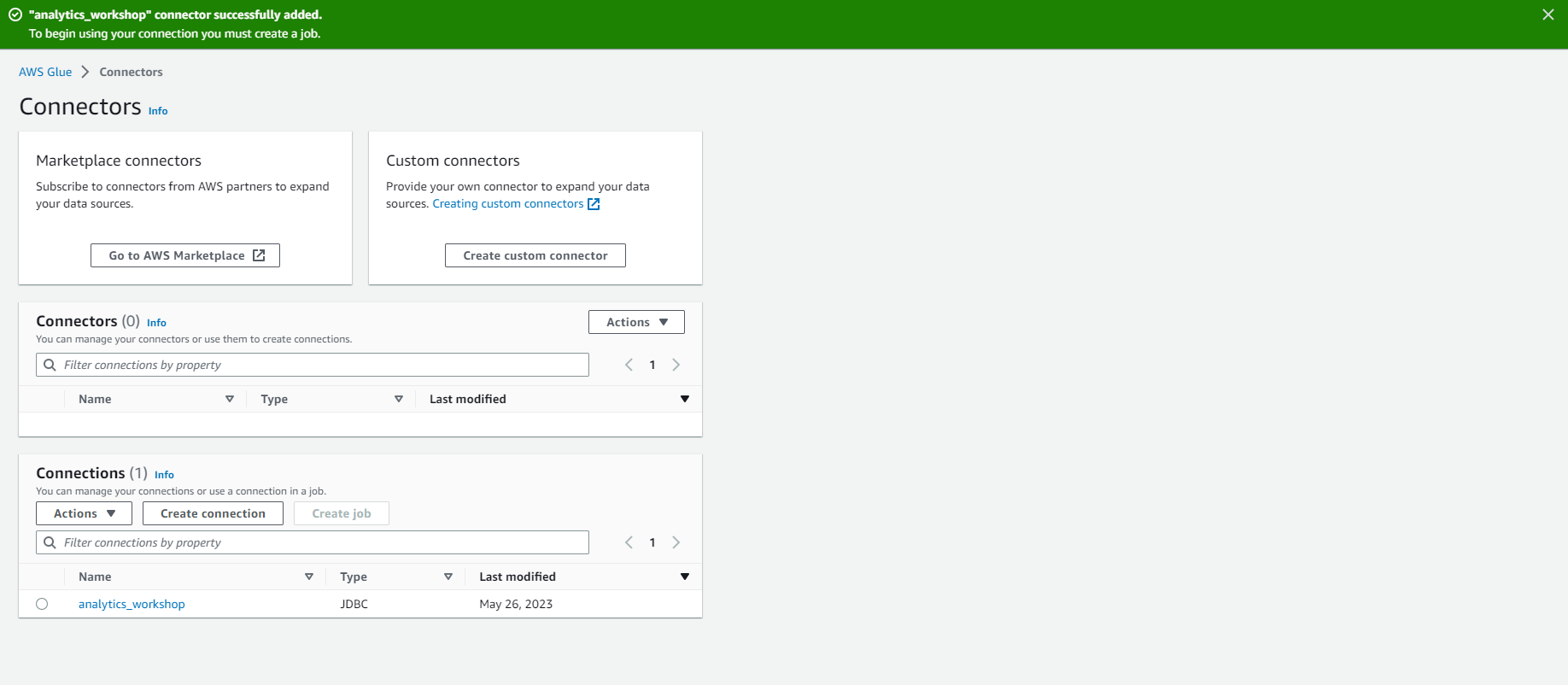
- Bây giờ bạn nên thấy kết nối analytics_workshop trong danh sách Connections.
Create schema và redshift tables.
- Truy cập: Redshift Query Editor
- Click Connect to database
- Connection: Create a new connection
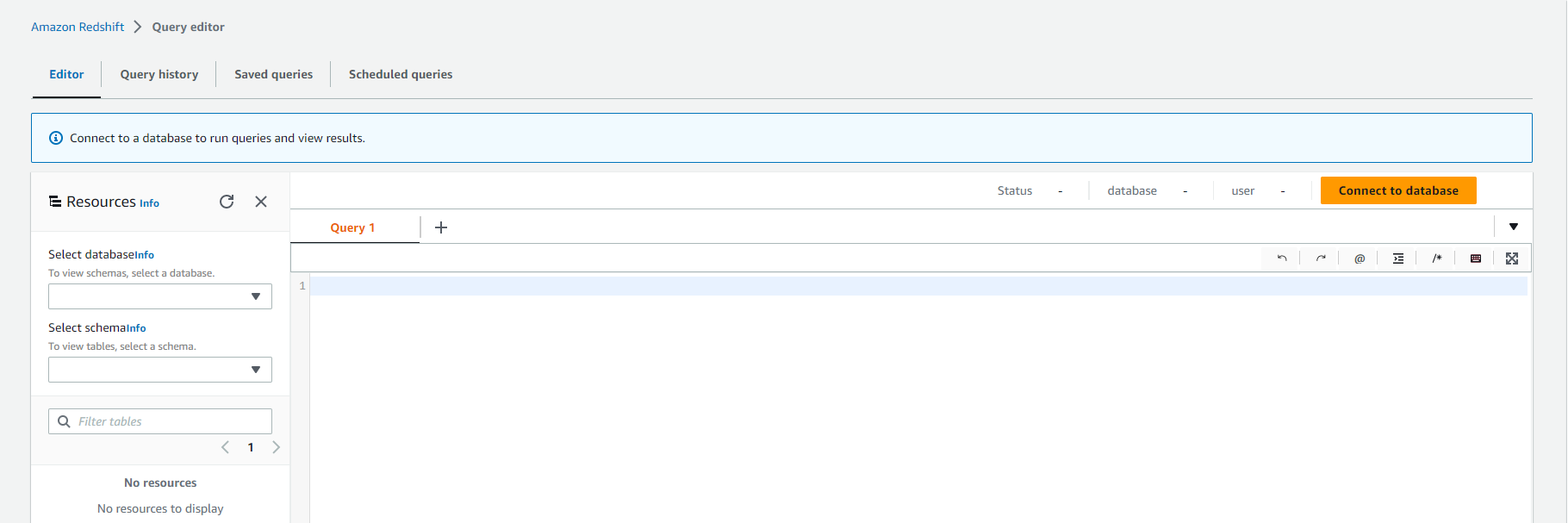
- Authentication: Temporary credentials
- cluster: redshift-cluster-1
- Database name: dev
- Database user: admin
- Click Connect
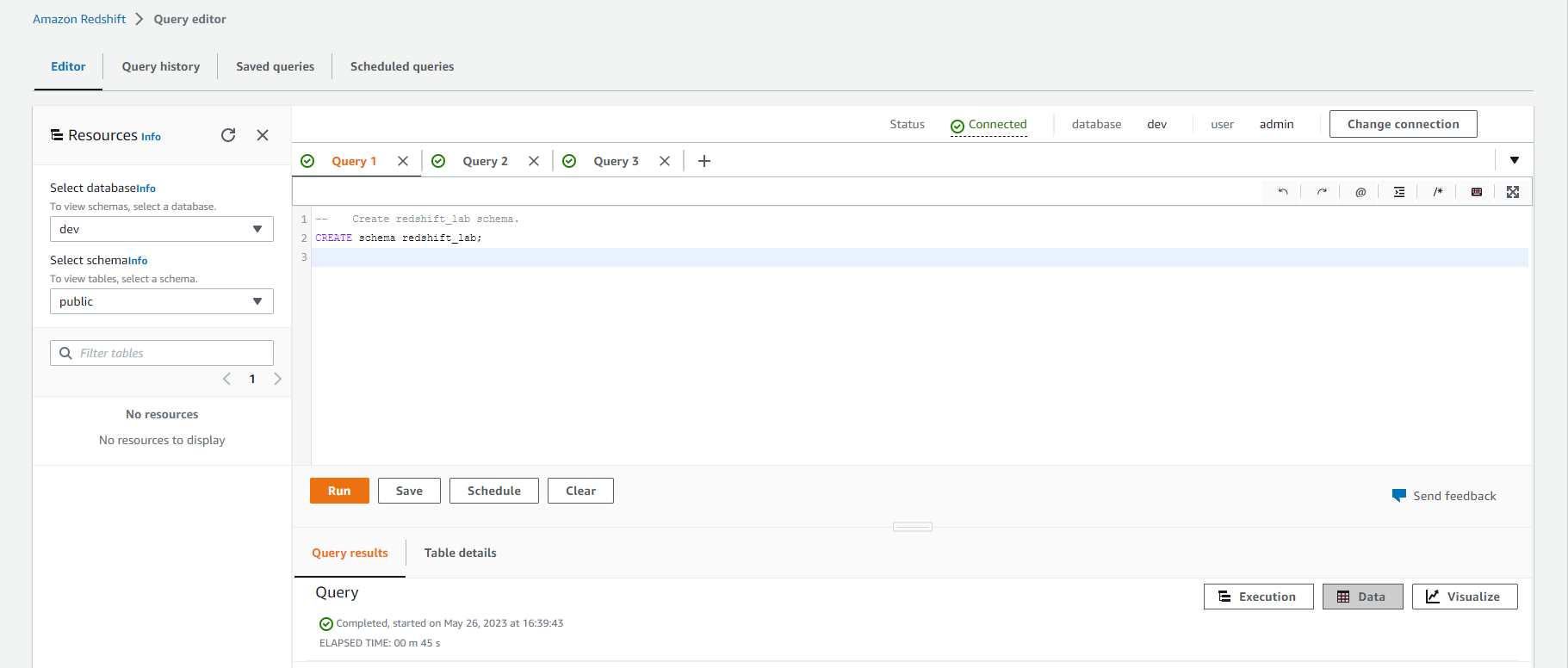
- Thực hiện các truy vấn dưới đây để tạo schema và bảng cho dữ liệu raw và reference.
-- Create redshift_lab schema.
CREATE schema redshift_lab;
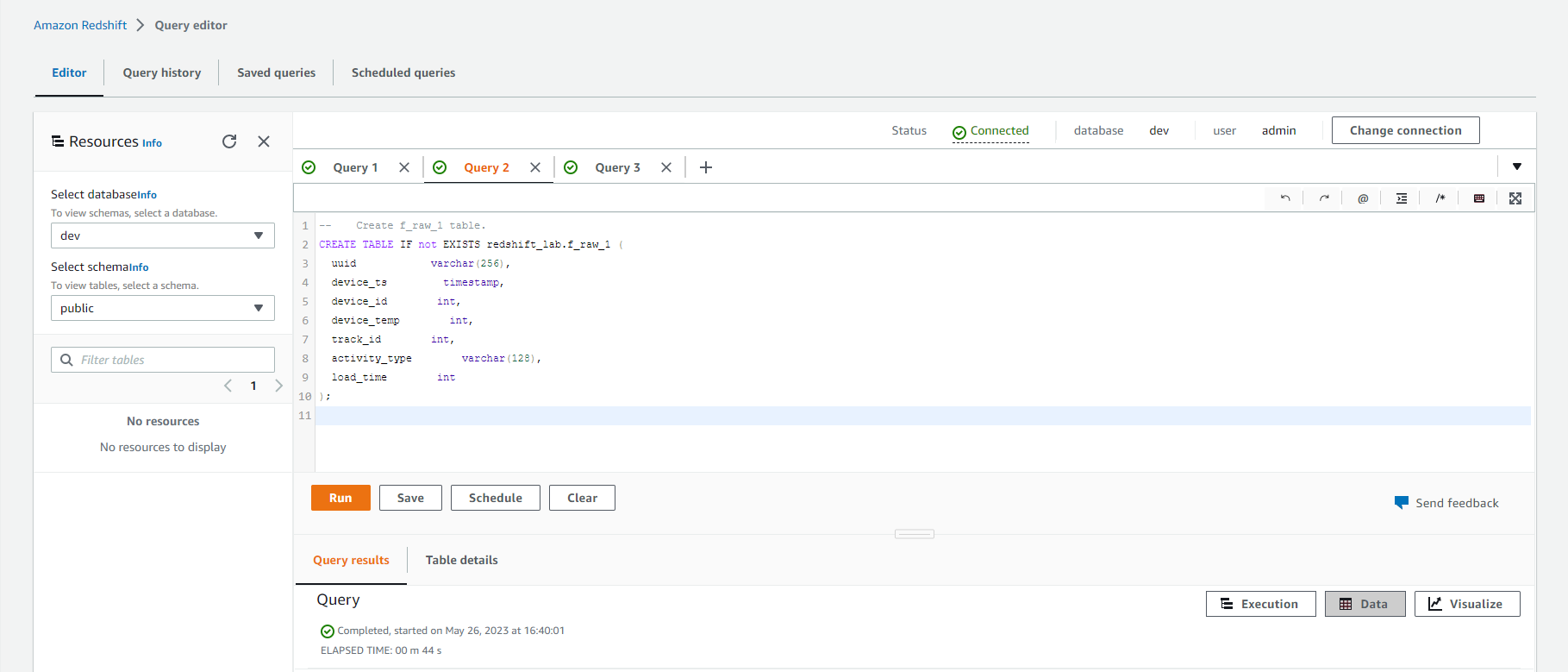
-- Create f_raw_1 table.
CREATE TABLE IF not EXISTS redshift_lab.f_raw_1 (
uuid varchar(256),
device_ts timestamp,
device_id int,
device_temp int,
track_id int,
activity_type varchar(128),
load_time int
);
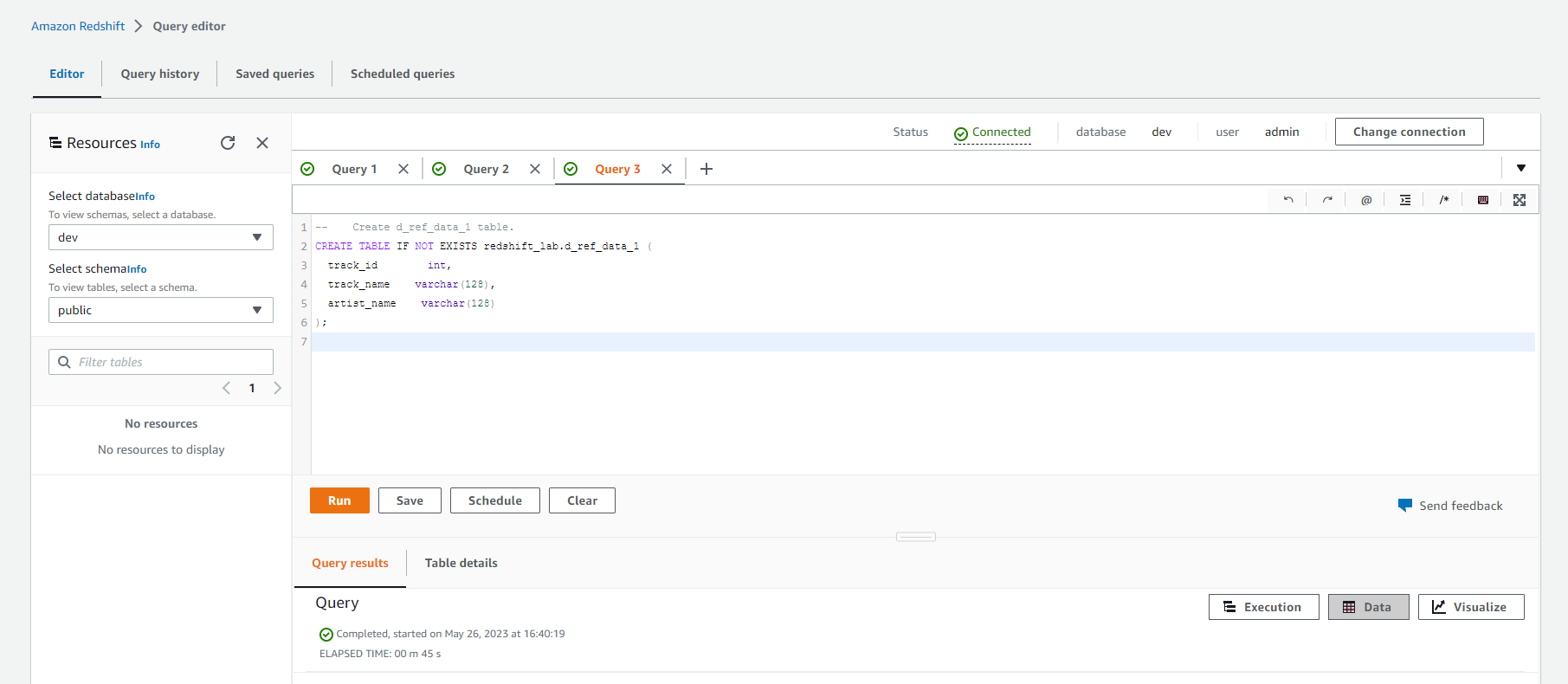
-- Create d_ref_data_1 table.
CREATE TABLE IF NOT EXISTS redshift_lab.d_ref_data_1 (
track_id int,
track_name varchar(128),
artist_name varchar(128)
);
Chuyển đổi và tải dữ liệu vào Redshift
- Sử dụng Jupyter Notebook trong AWS Glue để phát triển ETL tương tác
- Trong bước này, bạn sẽ tạo một job AWS Glue bằng Jupyter Notebook để phát triển tương tác các script Glue ETL bằng PySpark.
- Tải xuống và lưu tệp này trên máy tính của bạn: analytics-workshop-redshift-glueis-notebook.ipynb
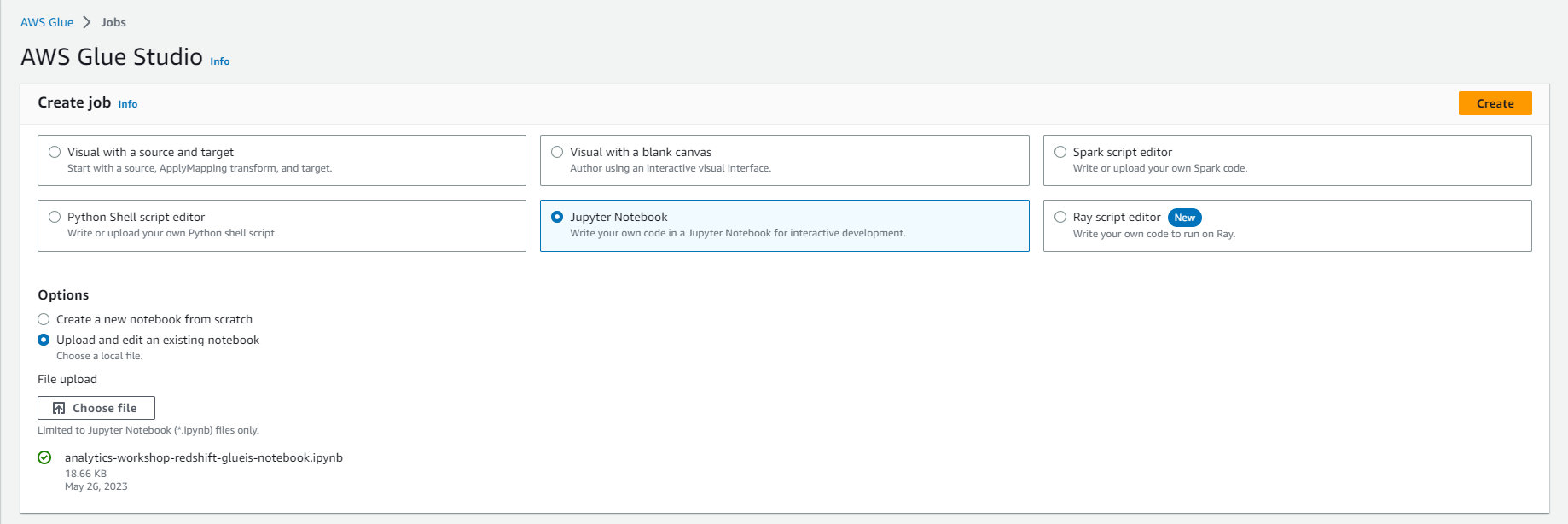
- Đi đến: Glue Studio jobs
- Chọn tùy chọn Jupyter Notebook
- Chọn Upload and edit an existing notebook
- Chọn vào Choose file
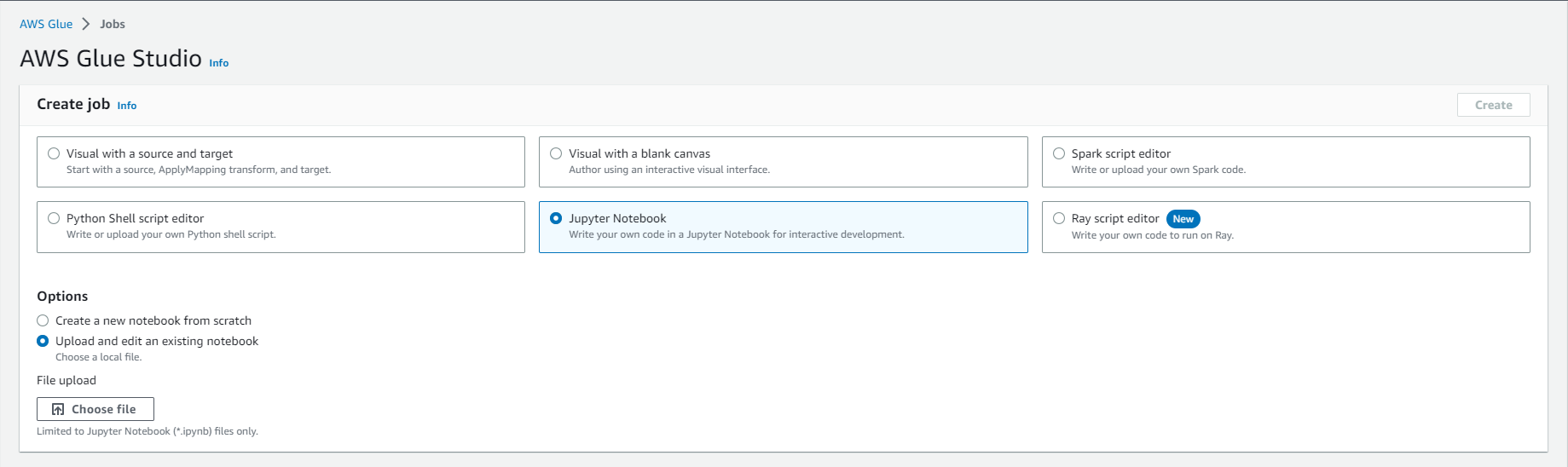
- Duyệt và tải lên analytics-workshop-redshift-glueis-notebook.ipynb mà bạn đã tải xuống trước đó
- Chọn vào Create
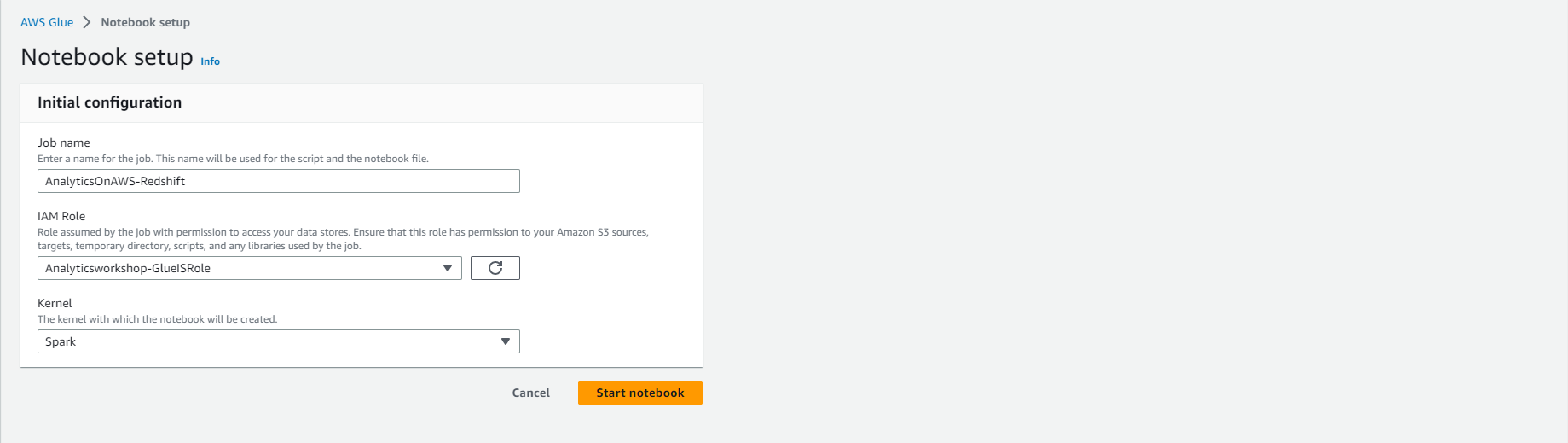
- Dưới Phần thiết lập Notebook và Cấu hình ban đầu
- Job name: AnalyticsOnAWS-Redshift
- IAM role Analyticsworkshop-GlueISRole
- Để Kernel mặc định là Spark
- Click Start notebook
- Sau khi notebook được khởi tạo, làm theo các hướng dẫn trong notebook
- Đọc và hiểu các hướng dẫn vì chúng giải thích các khái niệm Glue quan trọng
Validate - Dữ liệu đã được chuyển đổi / xử lý đã đến Redshift.
-
Sau khi ETL script chạy thành công, hãy mở Redshift Query Editor
-
Thực hiện các truy vấn sau để kiểm tra số lượng bản ghi trong bảng dữ liệu raw và reference table.
select count(1) from redshift_lab.f_raw_1;
select count(1) from redshift_lab.d_ref_data_1;
- Some queries to try
select
track_name,
artist_name,
count(1) frequency
from
redshift_lab.f_raw_1 fr
inner join
redshift_lab.d_ref_data_1 drf
on
fr.track_id = drf.track_id
where
activity_type = 'Running'
group by
track_name, artist_name
order by
frequency desc
limit 10;