Transform Data with AWS Glue DataBrew
Chuyển đổi dữ liệu với AWS Glue DataBrew
AWS Glue DataBrew là một công cụ chuẩn bị dữ liệu trực quan mới giúp cho các nhà phân tích dữ liệu và nhà khoa học dữ liệu dễ dàng làm sạch và chuẩn hóa dữ liệu để chuẩn bị cho phân tích và học máy. Bạn có thể lựa chọn từ hơn 250 phép biến đổi được xây dựng sẵn để tự động hóa các nhiệm vụ chuẩn bị dữ liệu, mà không cần viết mã. Bạn có thể tự động hóa việc lọc các ngoại lệ, chuyển đổi dữ liệu sang định dạng chuẩn, sửa các giá trị không hợp lệ và các nhiệm vụ khác. Sau khi dữ liệu của bạn đã sẵn sàng, bạn có thể ngay lập tức sử dụng nó cho các dự án phân tích và học máy. Bạn chỉ trả tiền cho những gì bạn sử dụng - không có cam kết trước.
Trong bài lab này, chúng ta sẽ thực hiện quá trình ETL tương tự như “Chuyển đổi dữ liệu với AWS Glue” (phiên tương tác) nhưng lần này chúng ta sẽ sử dụng AWS Glue DataBrew.
Các kết quả học được từ mô-đun này là gì? Thực hành với AWS Glue DataBrew, một công cụ chuẩn bị dữ liệu trực quan giúp cho các nhà phân tích dữ liệu và nhà khoa học dữ liệu dễ dàng làm sạch và chuẩn hóa dữ liệu để chuẩn bị cho phân tích và học máy.
- Vào Glue Databrew Console. Chọn Create project
- Nhập tên dự án: AnalyticsOnAWS-GlueDataBrew như được hiển thị trong ảnh chụp màn hình dưới đây.
- Dưới phần Select a dataset, chọn New dataset
- Trong New dataset details, nhập raw-dataset vào ô Dataset name như hình ảnh mô tả bên dưới.

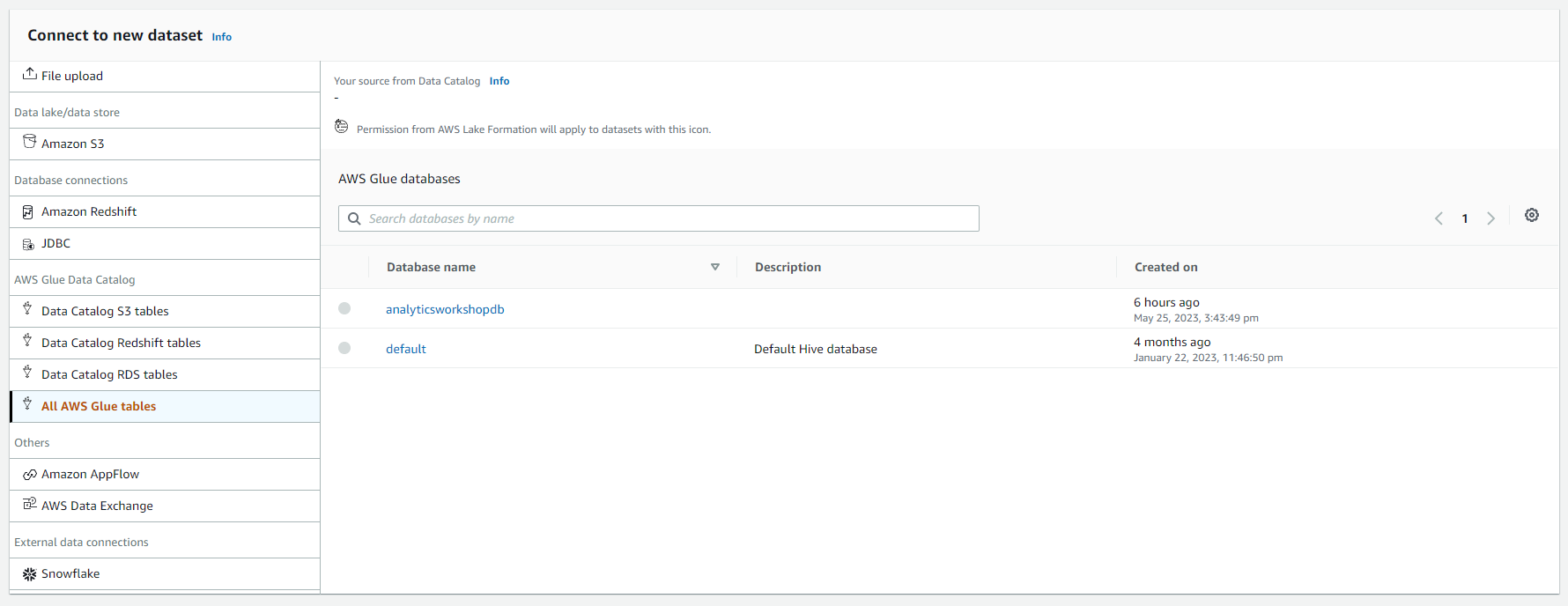
- Dưới Connect to new dataset
- Chọn All AWS Glue tables, bạn sẽ thấy tất cả các cơ sở dữ liệu trong AWS Glue Catalog như được hiển thị trong ảnh chụp màn hình dưới đây.
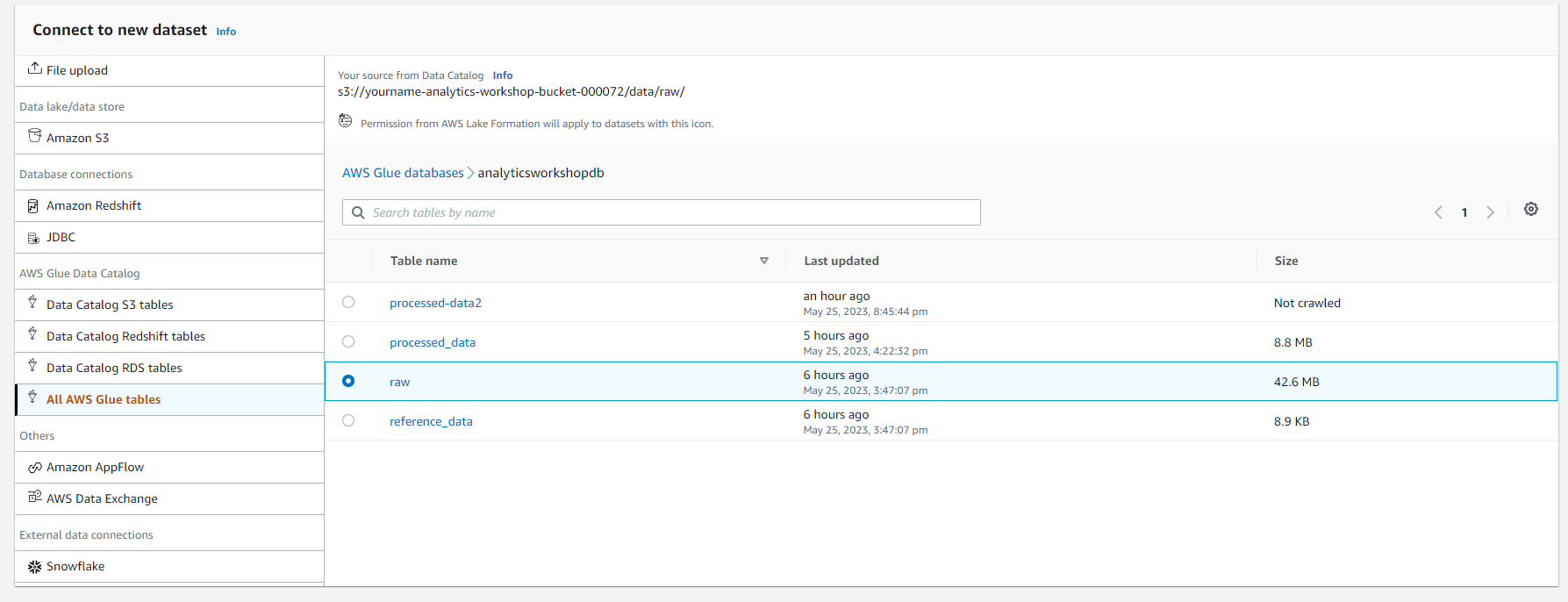
- Chọn vào analyticsworkshopdb. Chọn bảng raw
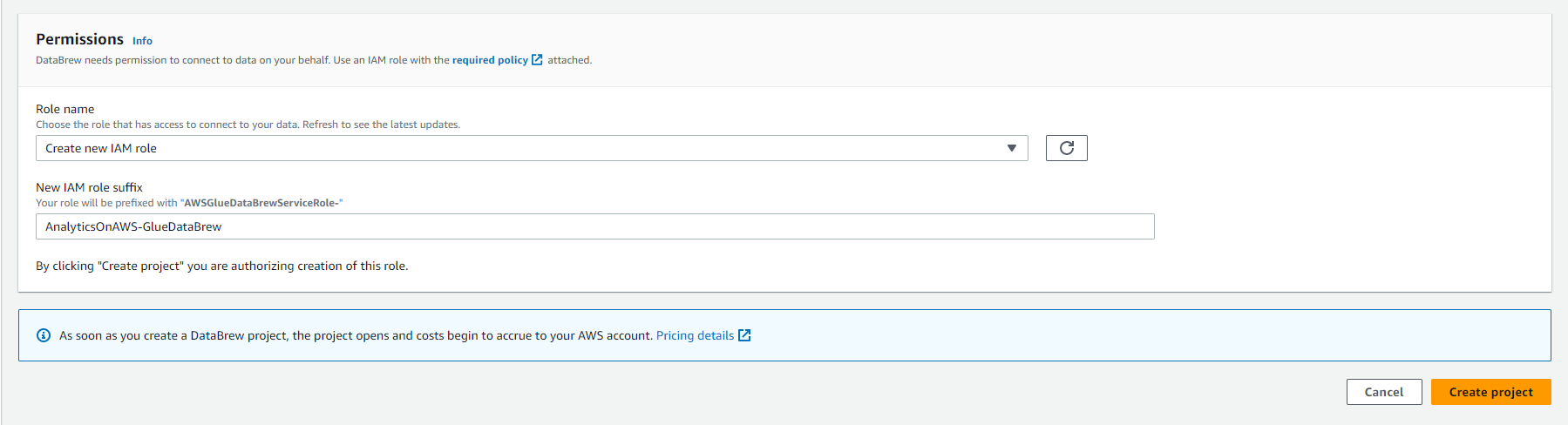
- Dưới Permissions
- Chọn Role name là Create new IAM role
- Nhập AnalyticsOnAWS-GlueDataBrew vào New IAM role suffix
- Click Create project
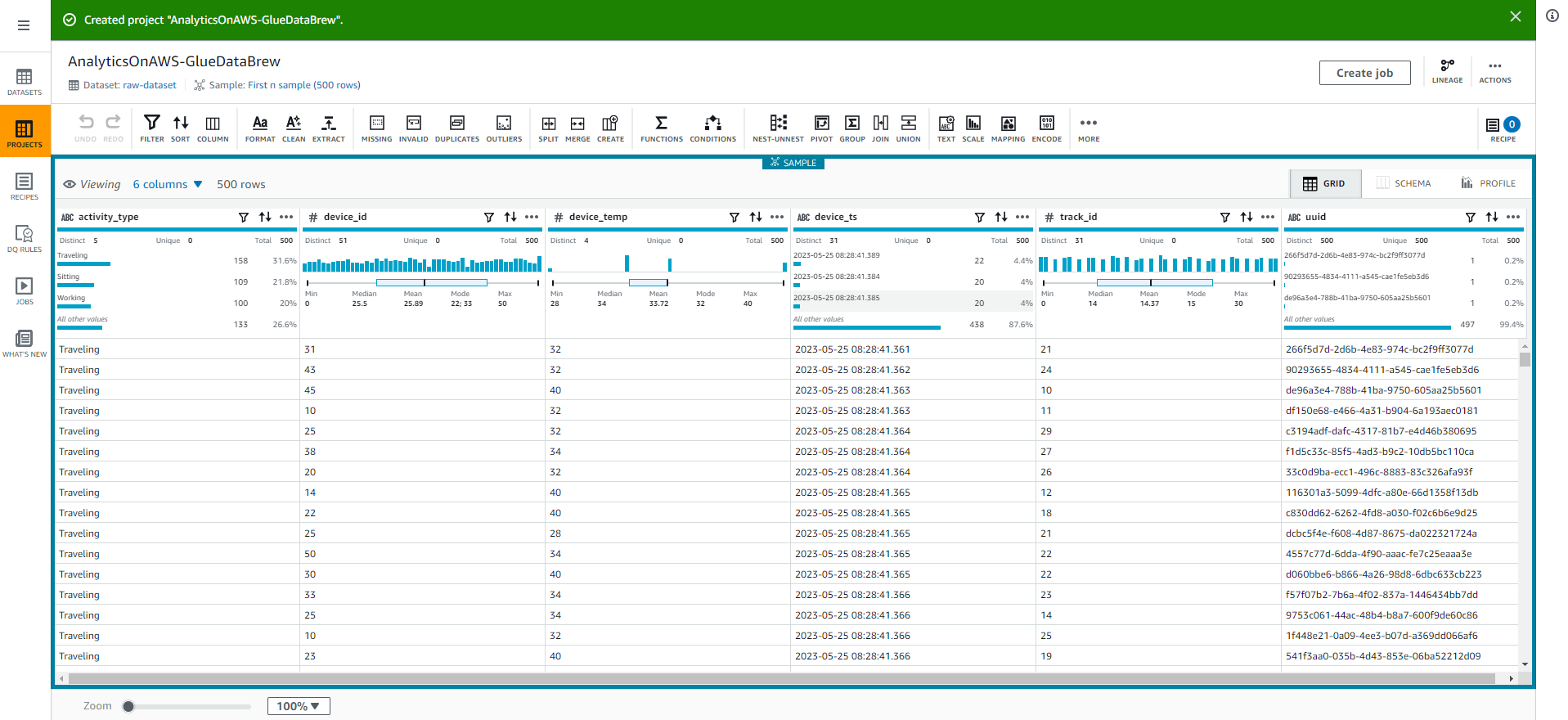
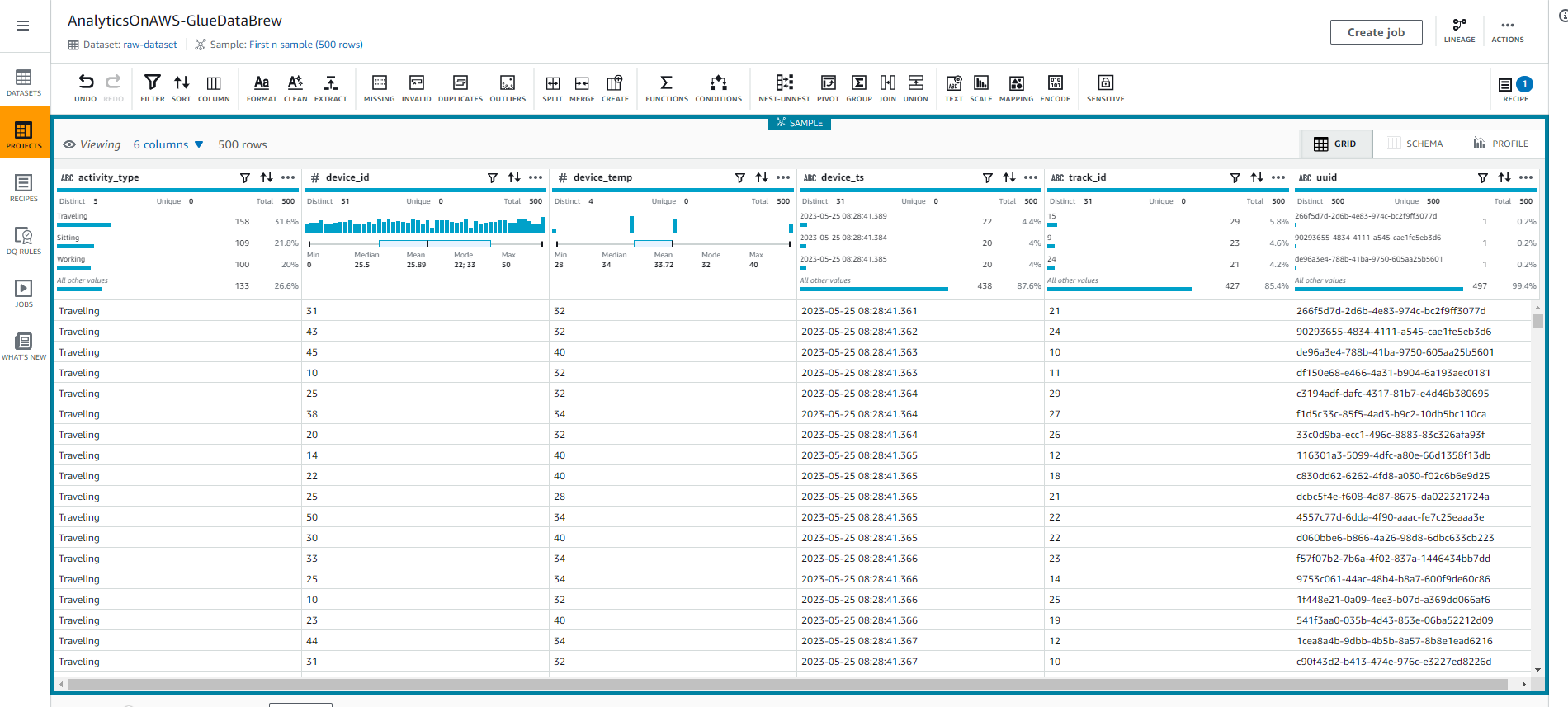
- Khi đã tạo phiên Glue DataBrew, bạn sẽ thấy như trong ảnh chụp màn hình dưới đây:
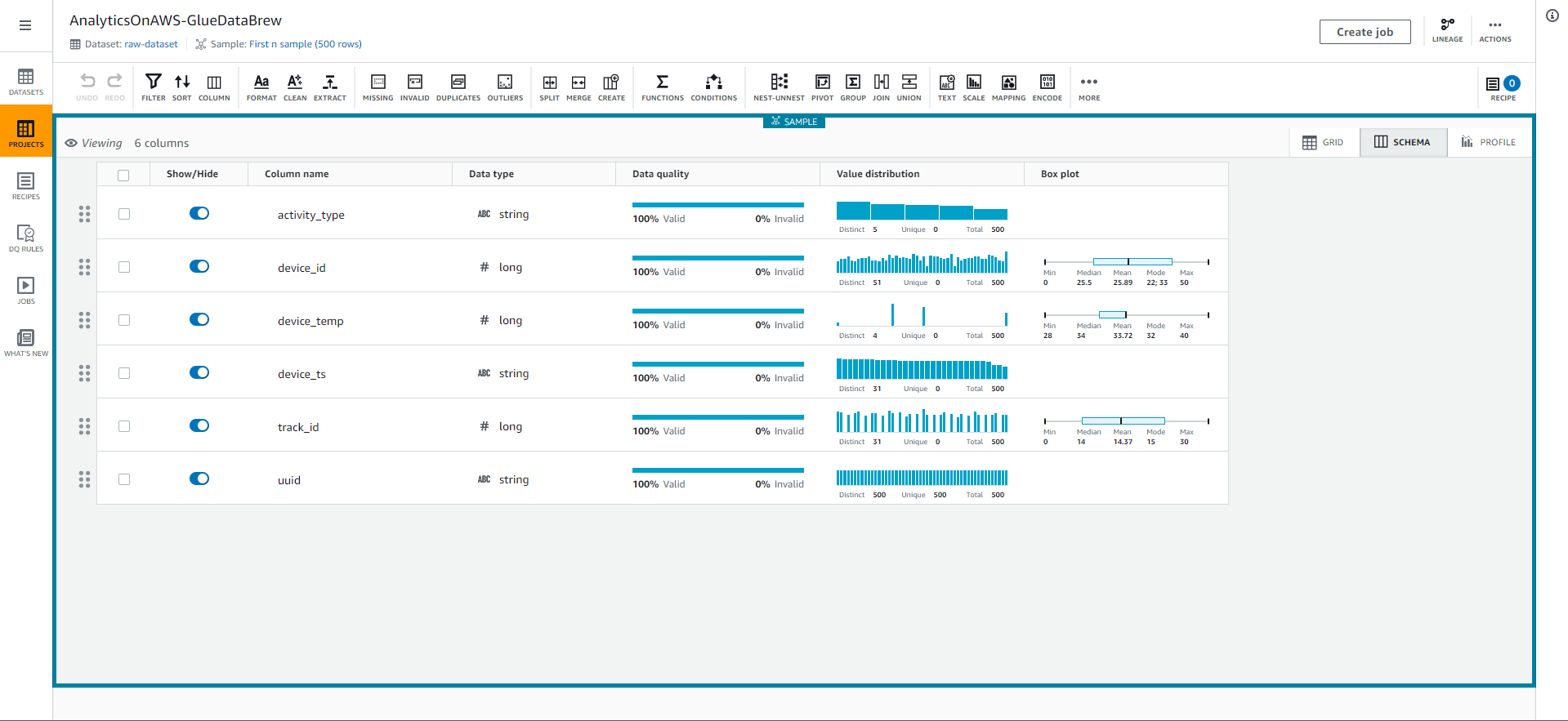
- Chọn vào tab SCHEMA ở góc phải trên cùng của màn hình để khám phá schema của bảng và các thuộc tính của nó như tên cột, kiểu dữ liệu, chất lượng dữ liệu, phân bố giá trị và biểu đồ hộp cho các giá trị số.
- Chọn vào tab GRID để quay lại chế độ xem lưới.
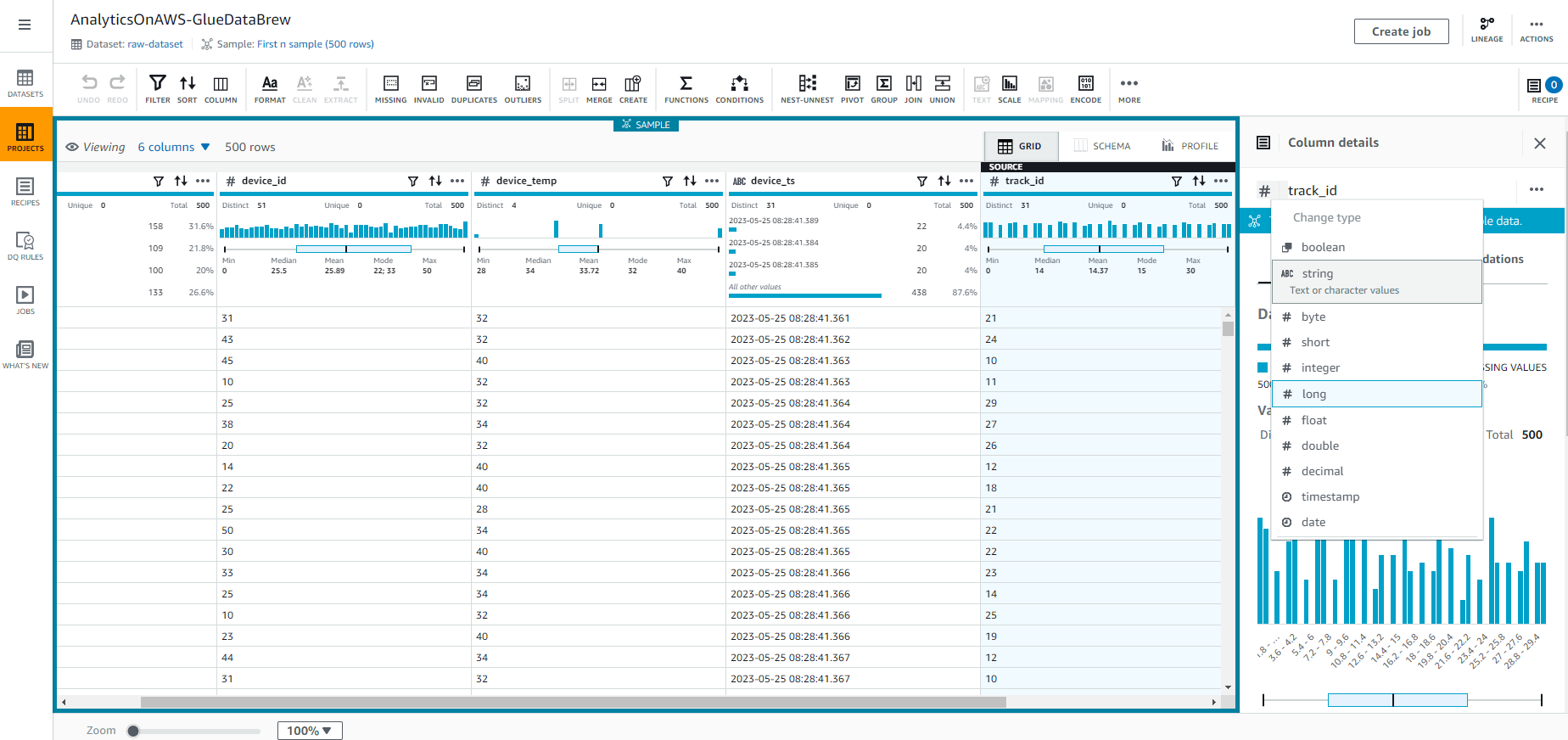
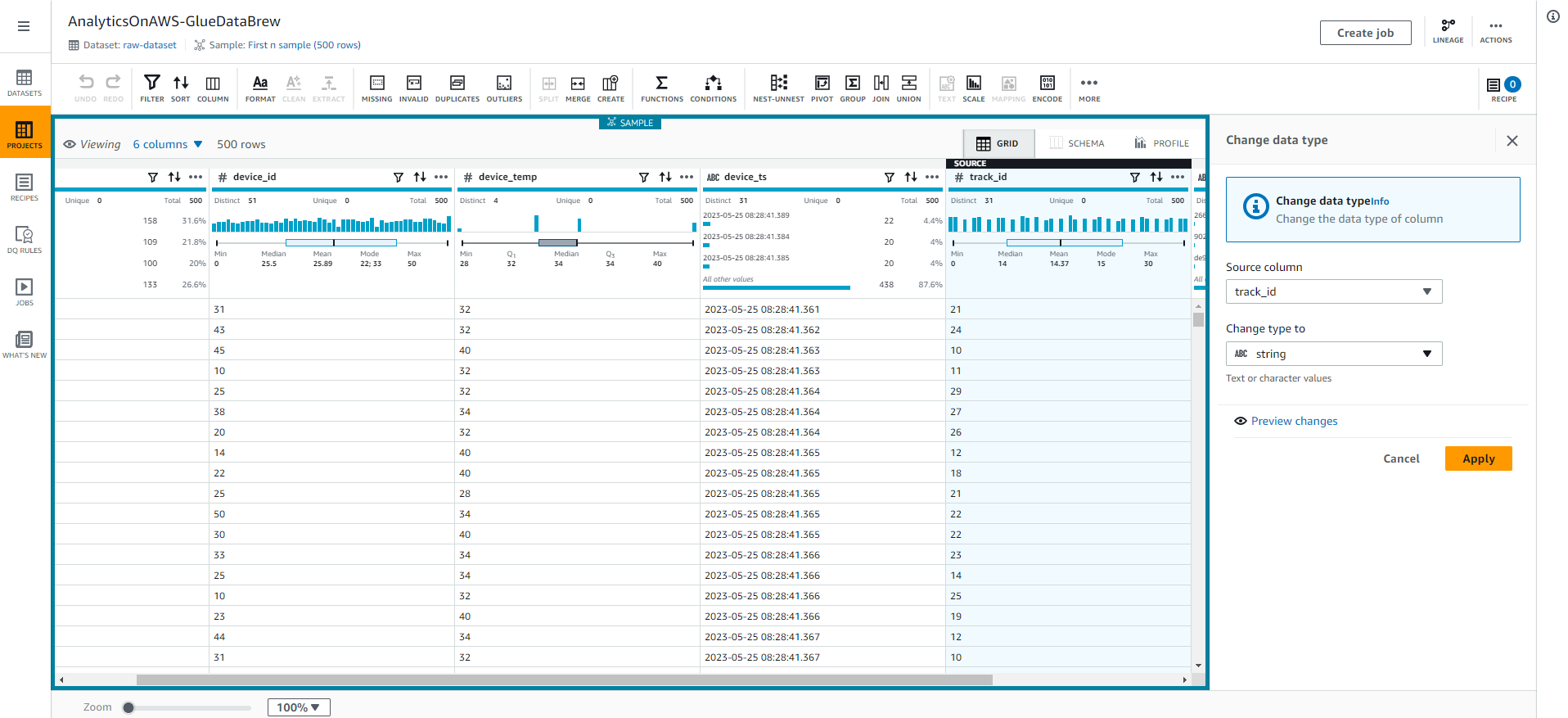
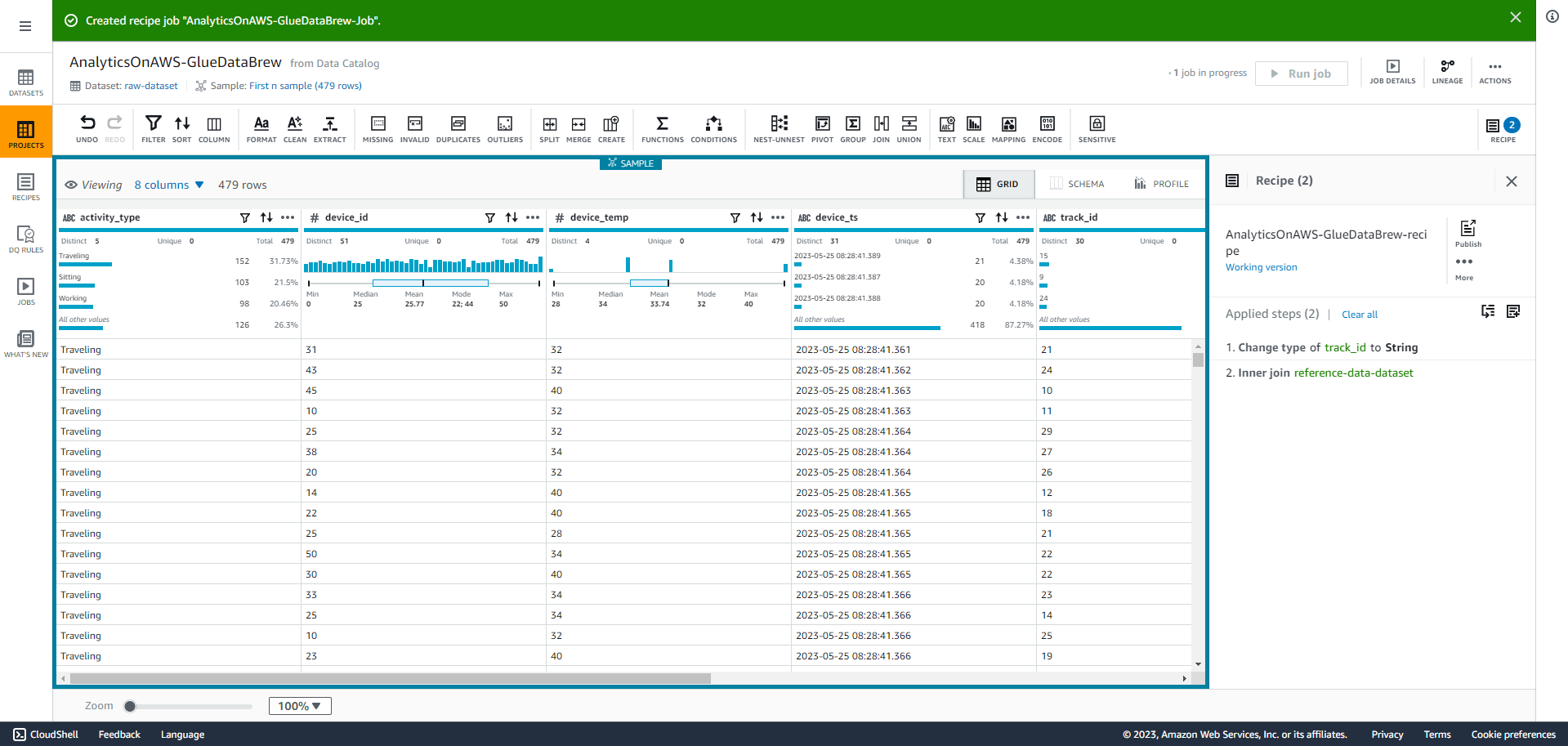
- Chúng ta sẽ thay đổi kiểu dữ liệu track_id bằng cách Chọn vào # trong cột track_id, và chọn kiểu chuỗi như được hiển thị trong ảnh chụp màn hình sau đây.
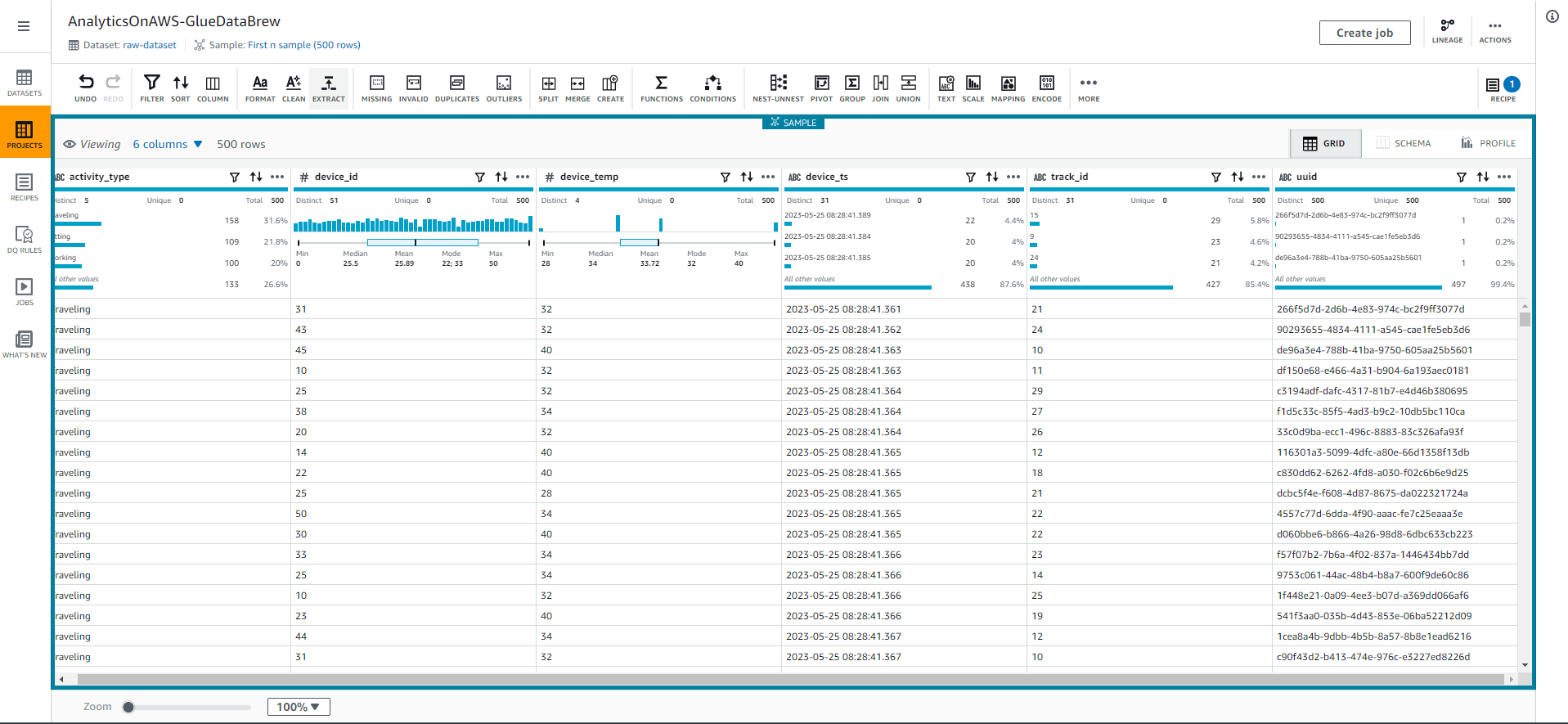
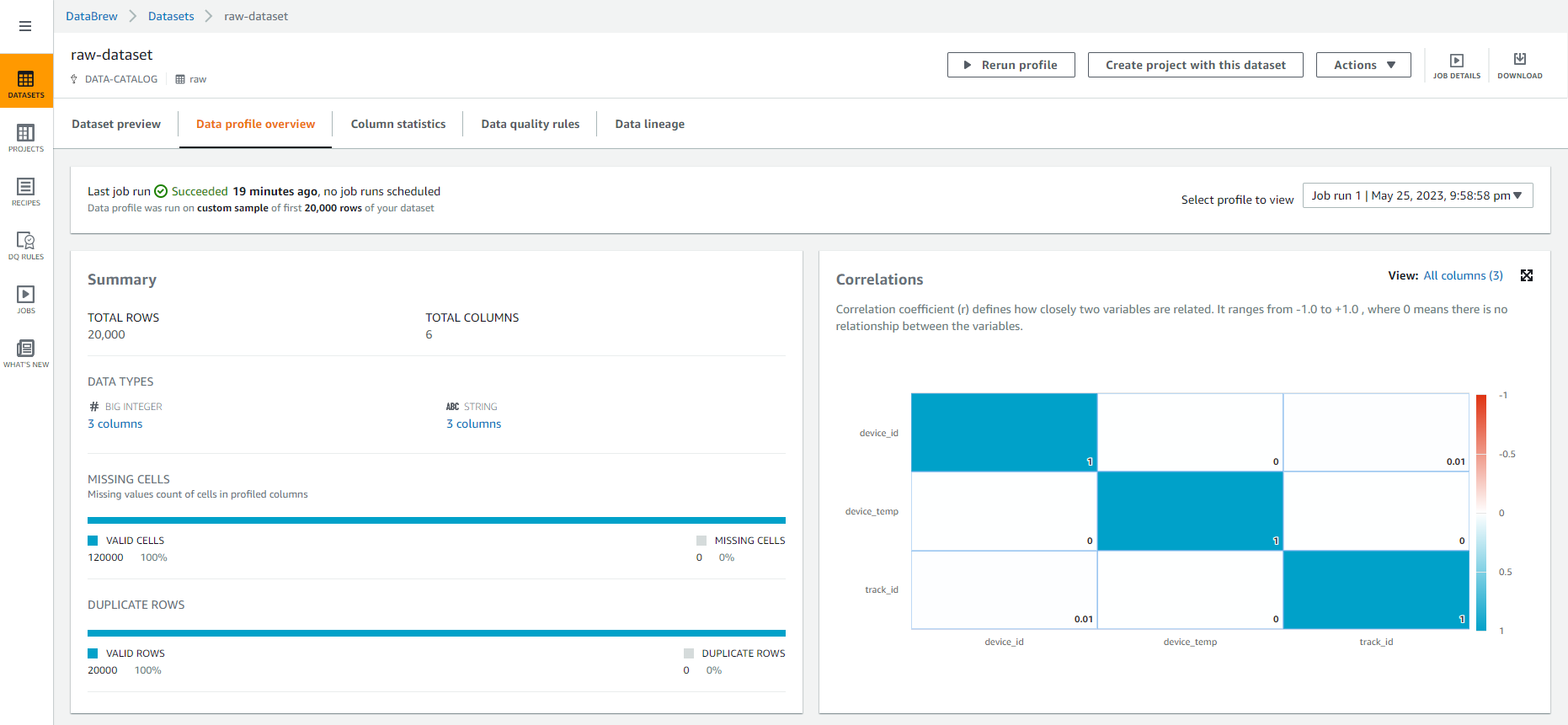
- Bây giờ, hãy phân tích dữ liệu để tìm hiểu các thống kê có ích như mối tương quan giữa các thuộc tính. Chọn vào tab PROFILE ở góc trên cùng bên phải màn hình, sau đó Chọn vào Run data profile.
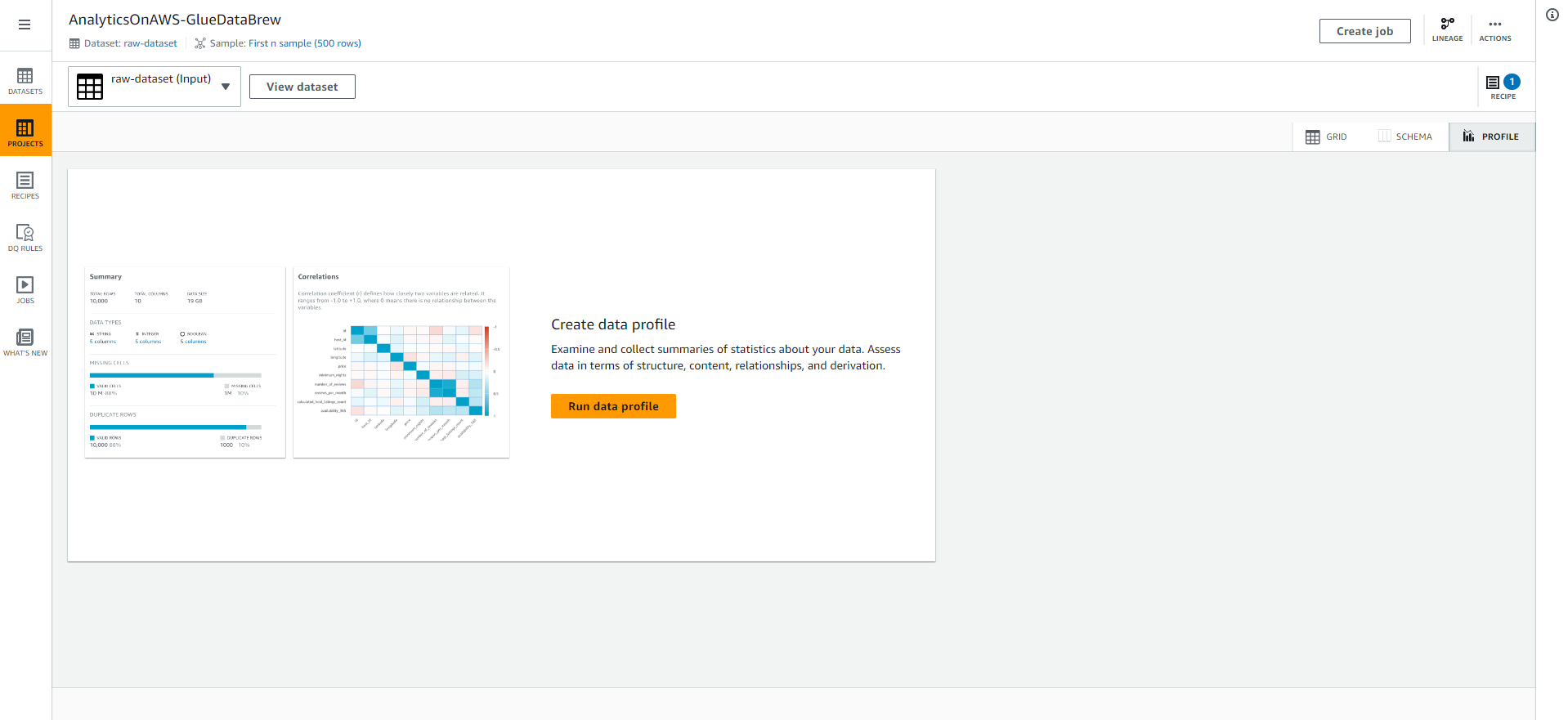
- Giữ nguyên Job name và Job run sample như là tùy chọn mặc định.
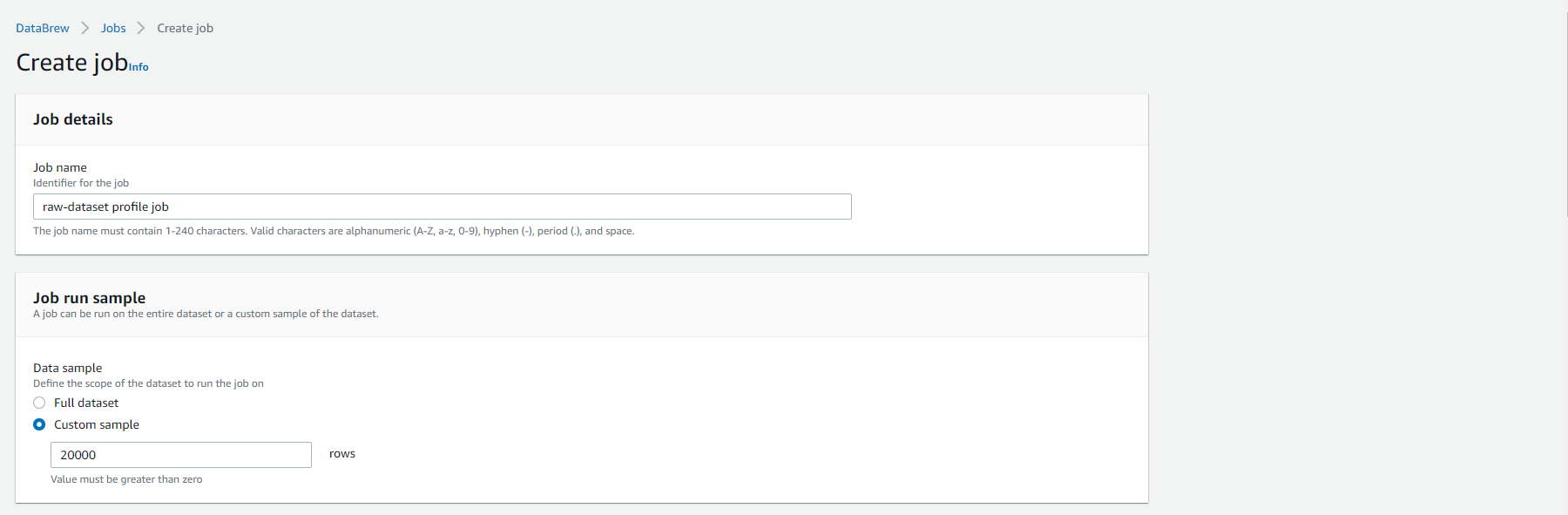
- Hãy chỉ định vị trí S3 dưới dạng tên bucket của bạn: s3://<tên-bucket-của-bạn>-analytics-workshop-bucket/ để lưu kết quả job. Đừng quên thay thế phần trong đường dẫn S3. Để tùy chọn Mở mã hóa cho tệp kết quả job không được chọn.
- Dưới Permissions, chọn Role name đã tạo
- Chọn Create and run job
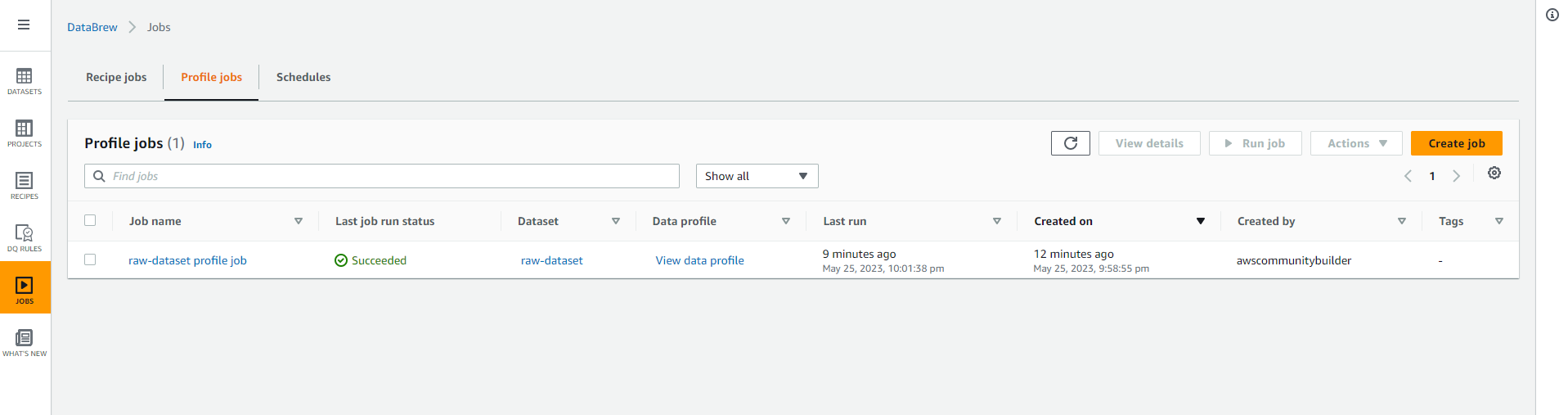
- Bạn nên nhận được kết quả tương tự như hình ảnh được hiển thị bên dưới, điều đó có nghĩa là Glue Databrew đã bắt đầu phân tích dữ liệu của bạn.
- Chọn vào tab GRID để quay lại chế độ xem lưới.
- Chọn vào Join.
- Click Connect new dataset
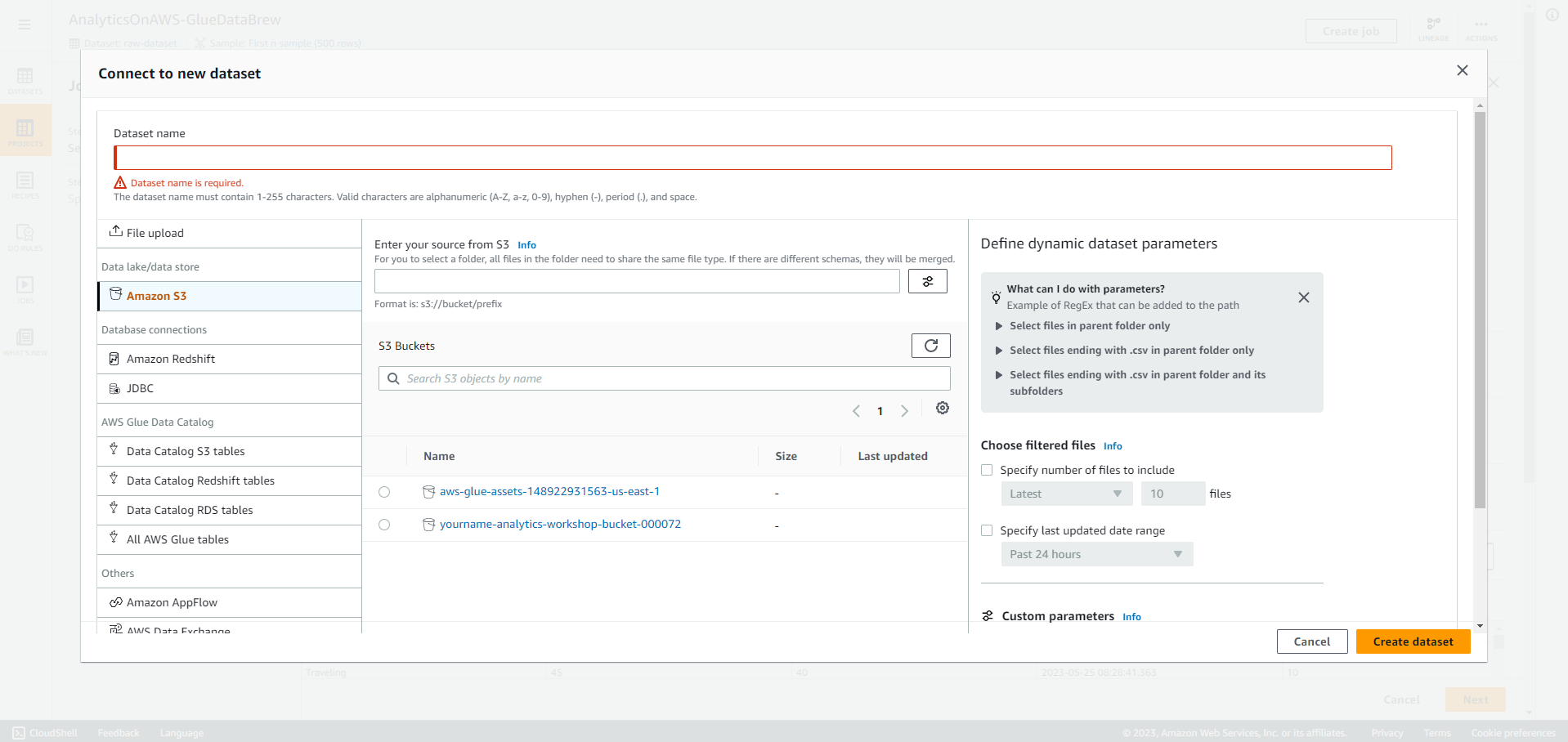
- Click All AWS Glue tables, và click analyticsworkshopdb
-
Click reference_data
-
Dataset name - reference-data-dataset
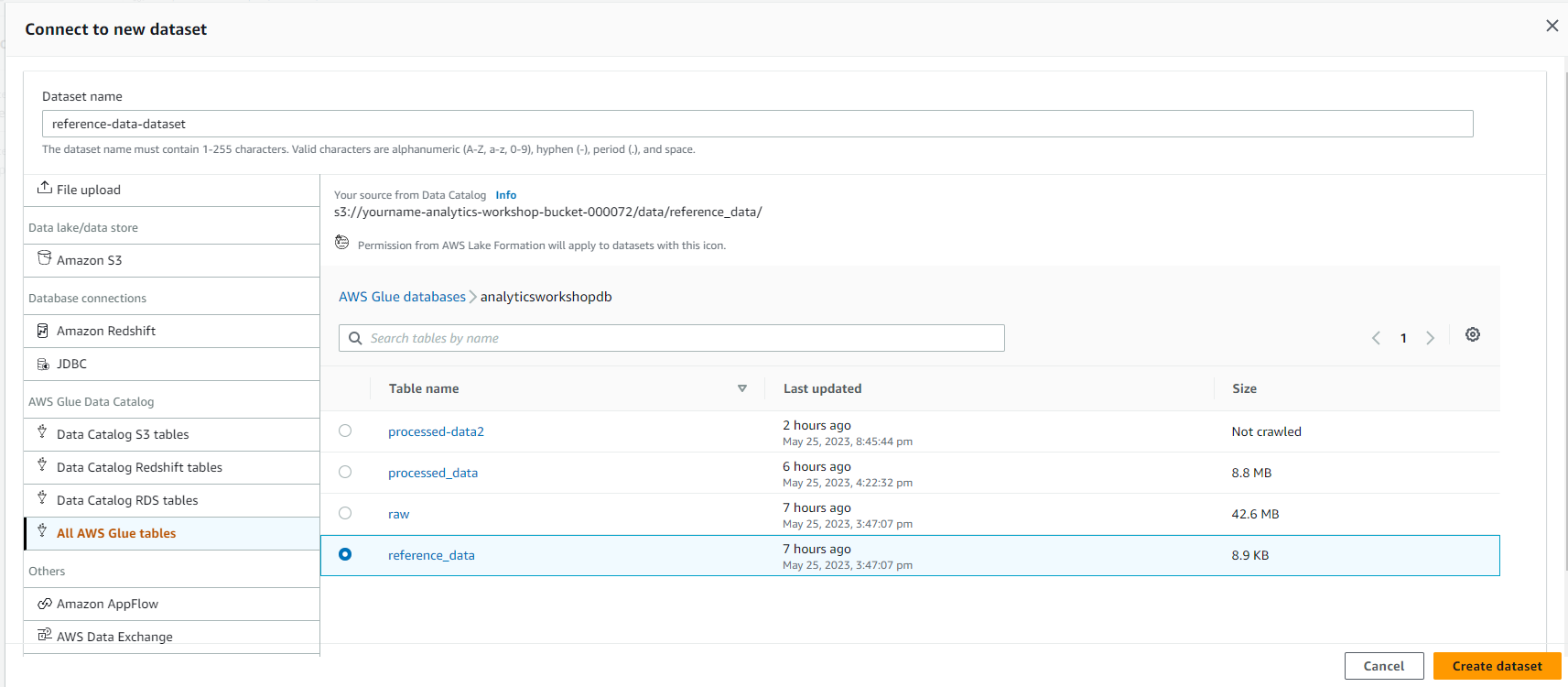
- Bạn nên nhìn thấy màn hình tương tự như hình ảnh dưới đây, Chọn vào Next.
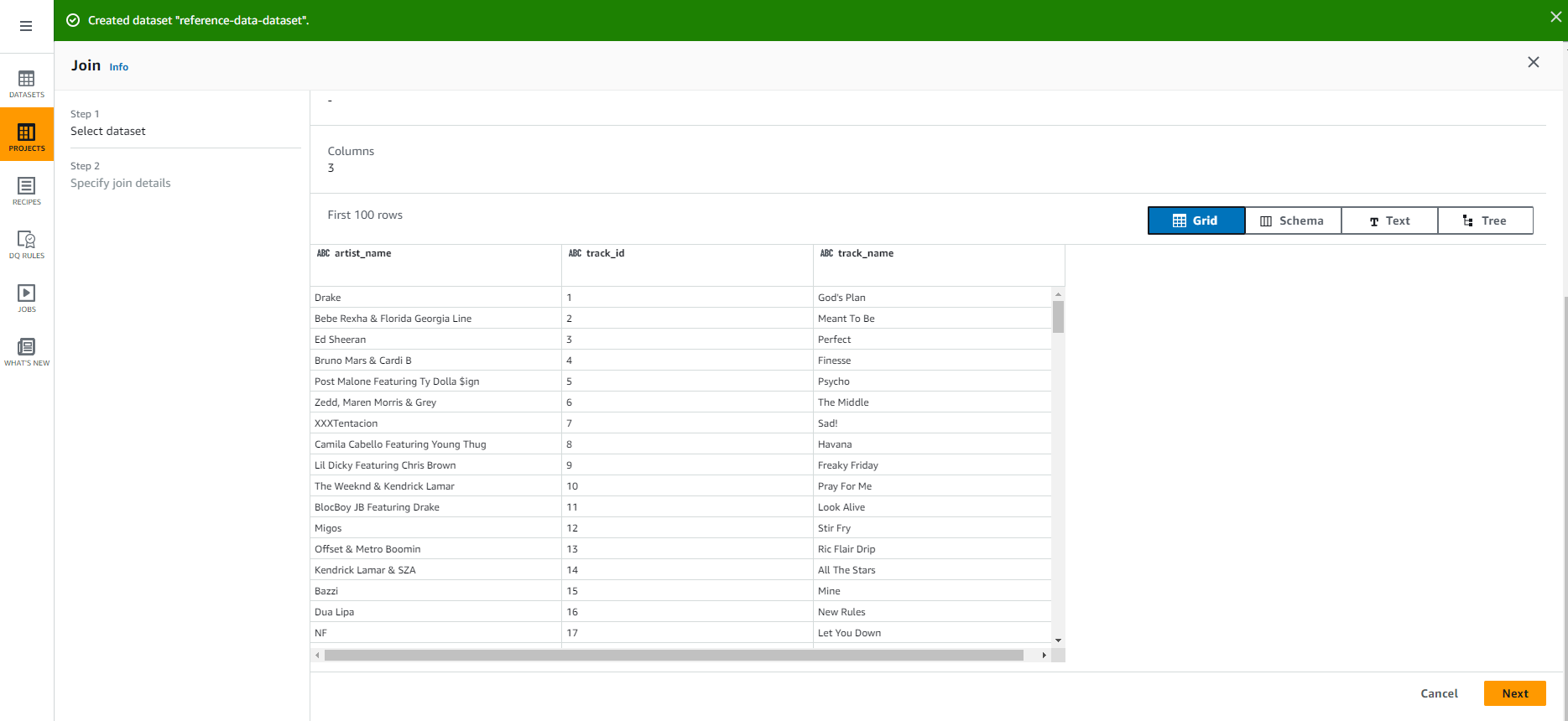
- Chọn track_id từ raw-dataset
-
Chọn track_id từ reference-data-set
-
Bỏ chọn track_id từ Table B
-
Chọn vào Finish
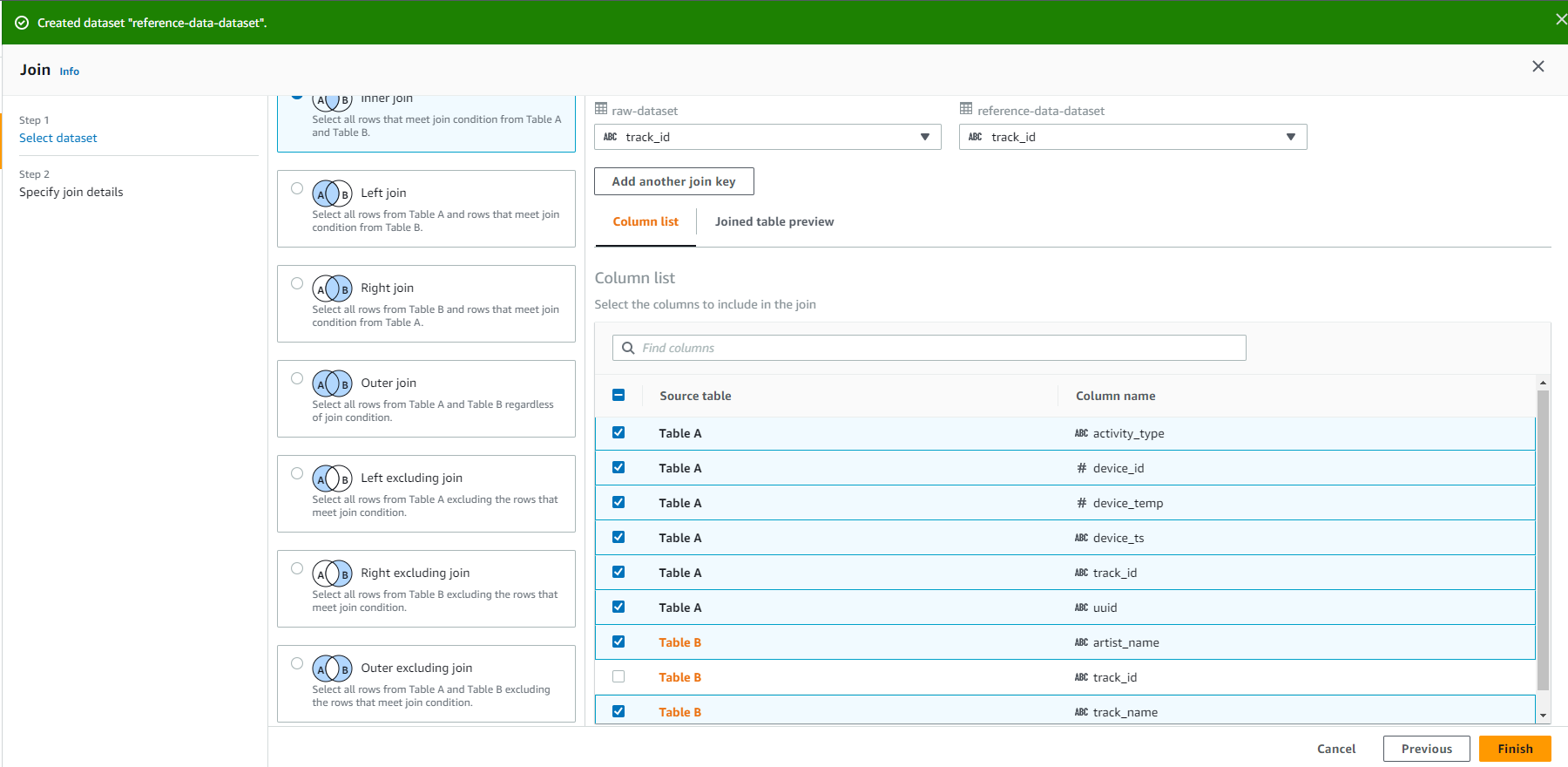
- Bạn nên xem kết quả như được hiển thị trong ảnh chụp màn hình dưới đây:
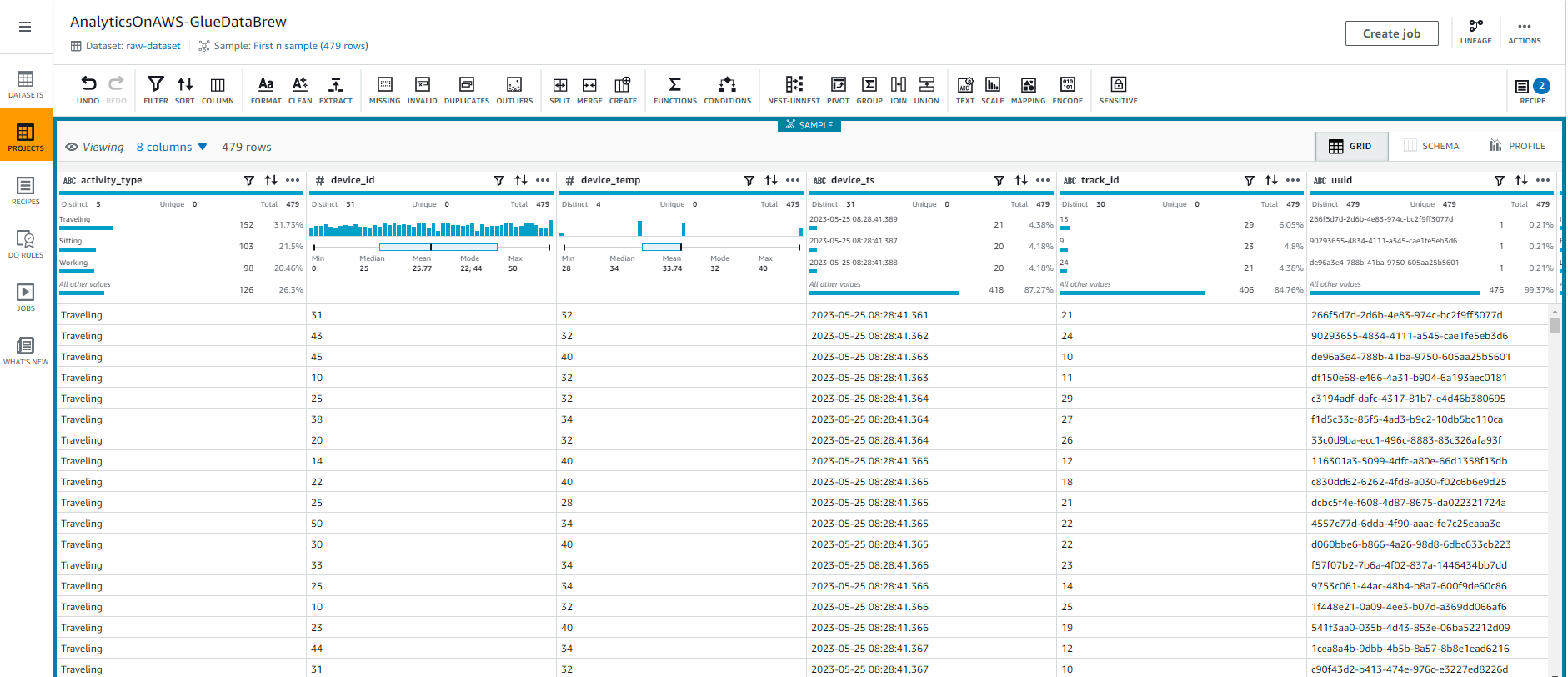
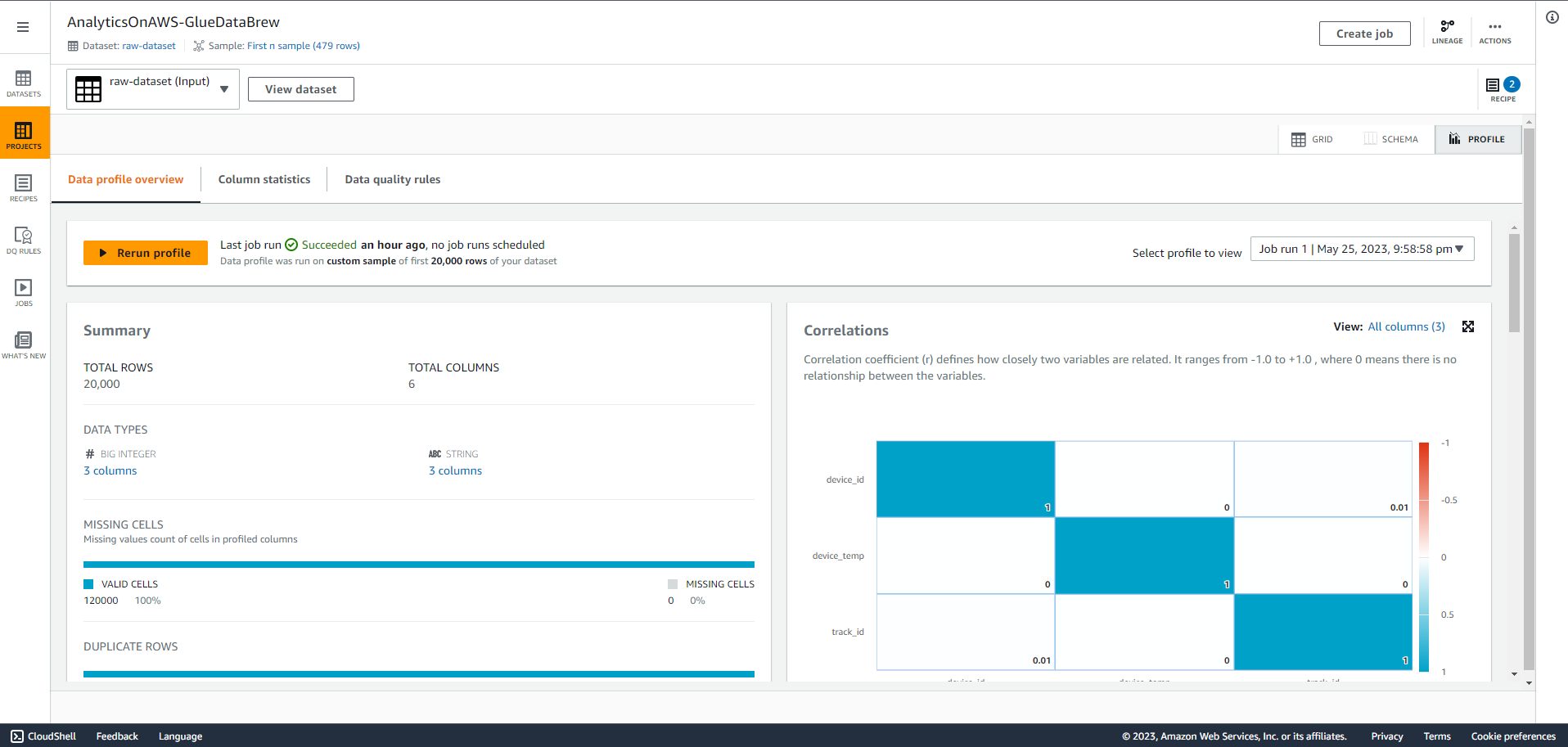
- Chọn vào “PROFILE” để xem kết quả phân tích dữ liệu gốc của bạn như tổng quan, ô trống, hàng trùng, tương quan, phân phối giá trị và thống kê cột. Điều này sẽ cung cấp cho bạn một cái nhìn sâu hơn về dữ liệu của bạn.
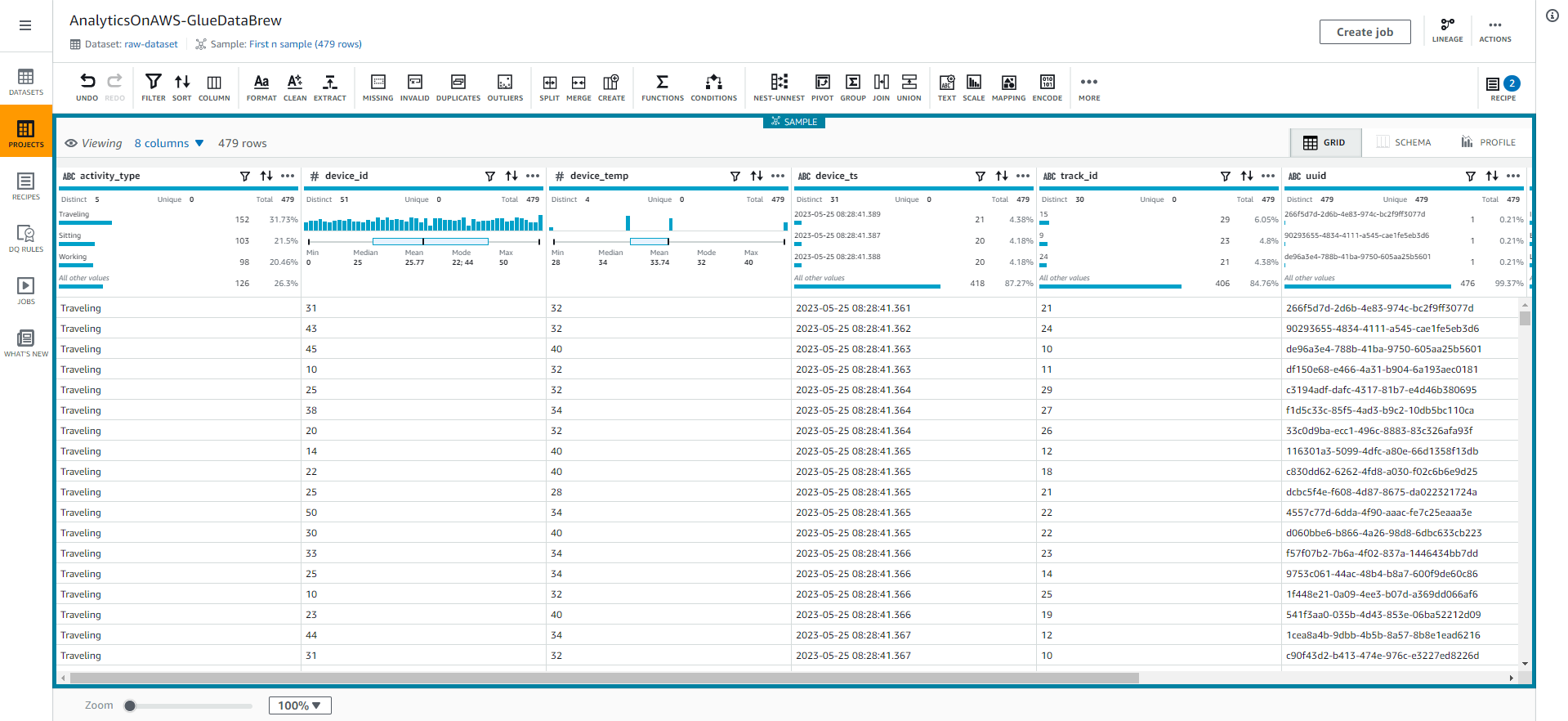
- Chọn vào LINEAGE ở góc phải trên cùng. Bạn nên có thể nhìn thấy dòng dữ liệu (data lineage), được biểu diễn một cách hình ảnh để cung cấp hiểu biết về luồng dữ liệu với các quá trình biến đổi liên quan ở tất cả các bước từ nguồn đến đích.
- Quay lại chế độ xem GRID, và Chọn vào Create job.
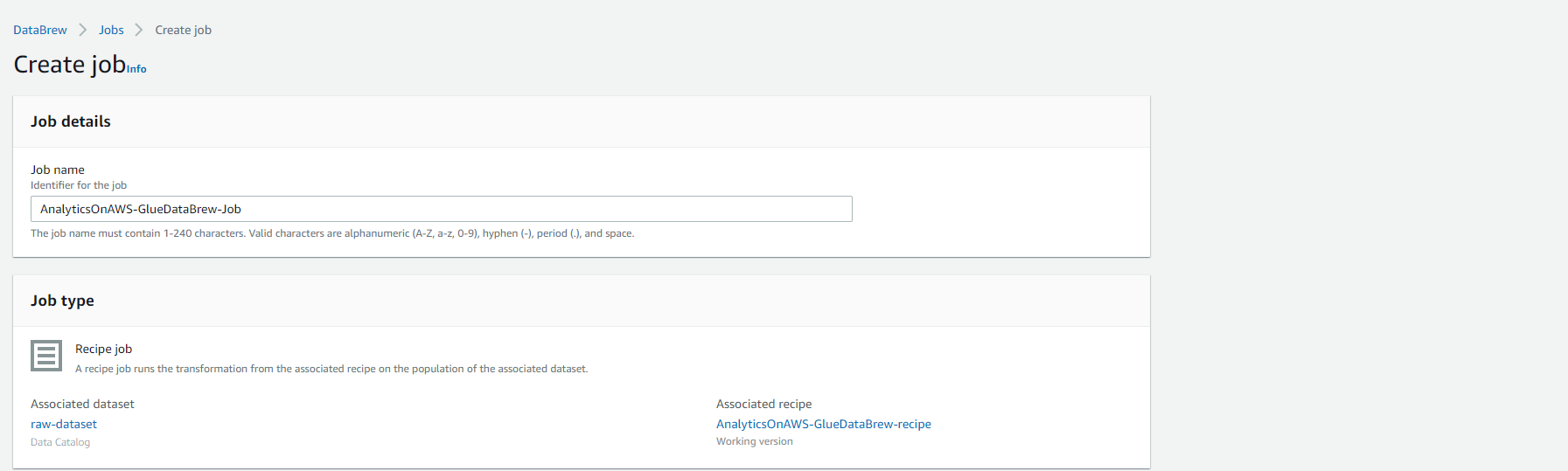
- Điền các giá trị sau đây:
- Dưới phần Job details
- Job name: AnalyticsOnAWS-GlueDataBrew-Job
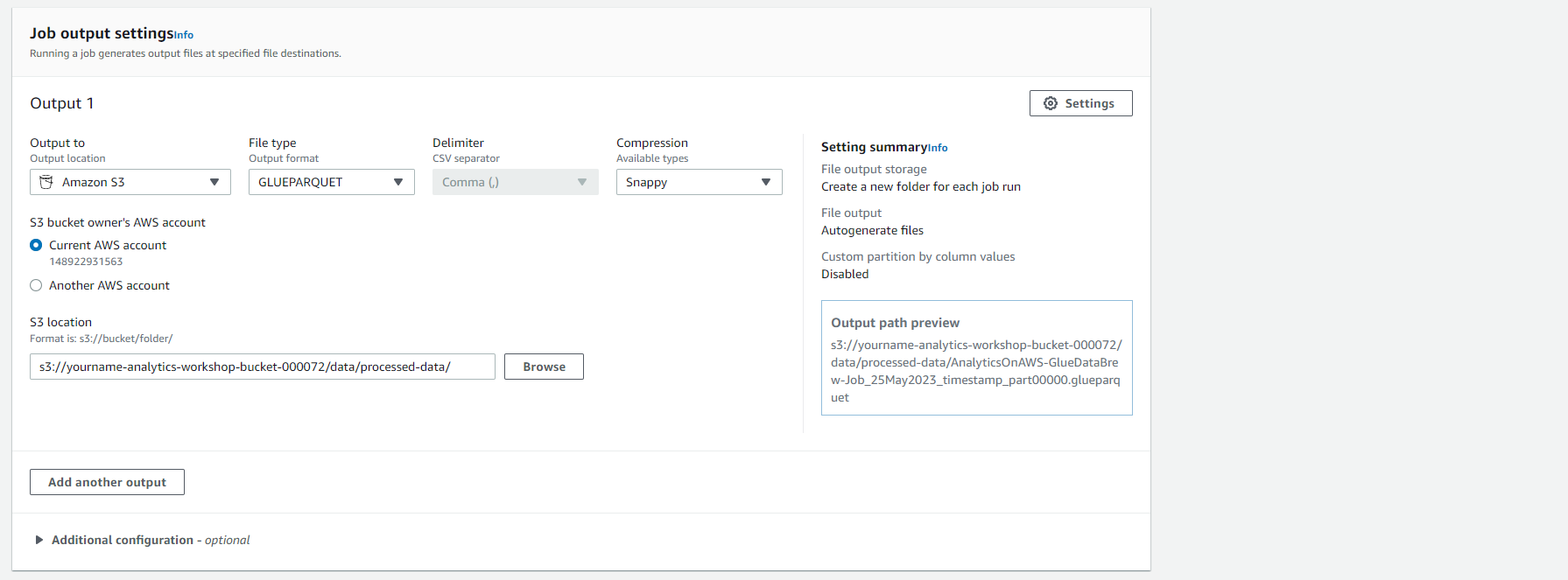
- Dưới Job output settings
- File type: GlueParquet
- S3 location: s3://-analytics-workshop-bucket/data/processed-data/
- Cuộn xuống phần “Permission” và chọn tên role mà bạn đã tạo trong bước đầu tiên, sau đó Chọn vào “Create and run job”.

- Bạn nên xem có 1 job đang tiến hành
- Chọn vào mục “Jobs” trên menu bên trái, bạn sẽ thấy ảnh chụp màn hình dưới đây, sau đó Chọn vào Job name (liên kết). Ở đây, bạn có thể khám phá lịch sử chạy job, chi tiết job và dòng dữ liệu giống như trong ảnh chụp màn hình dưới đây:
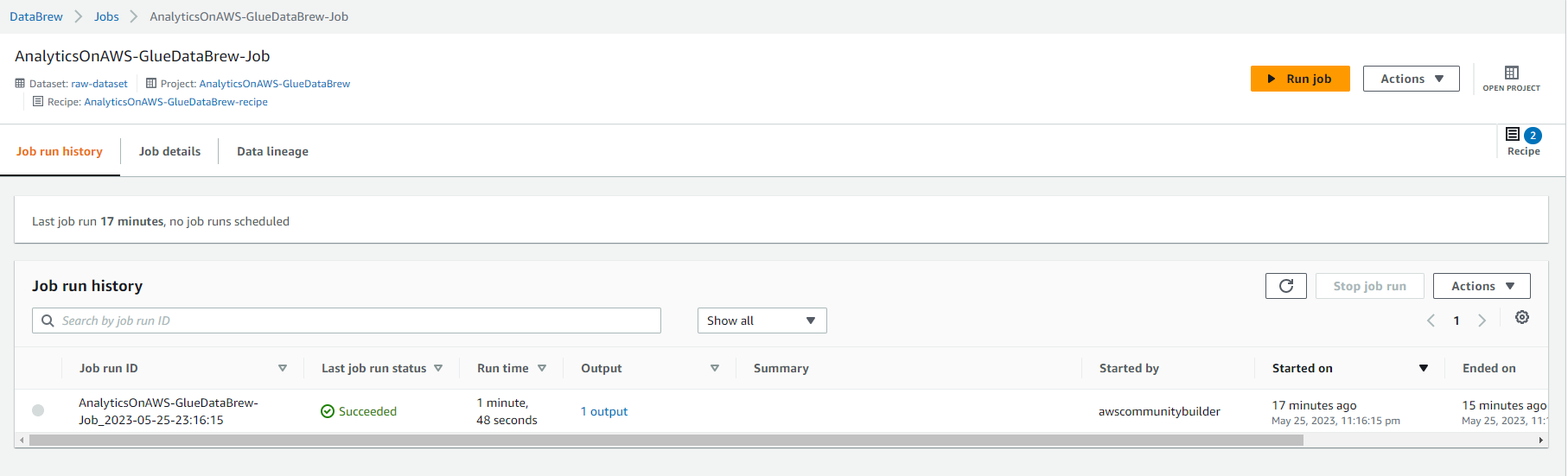
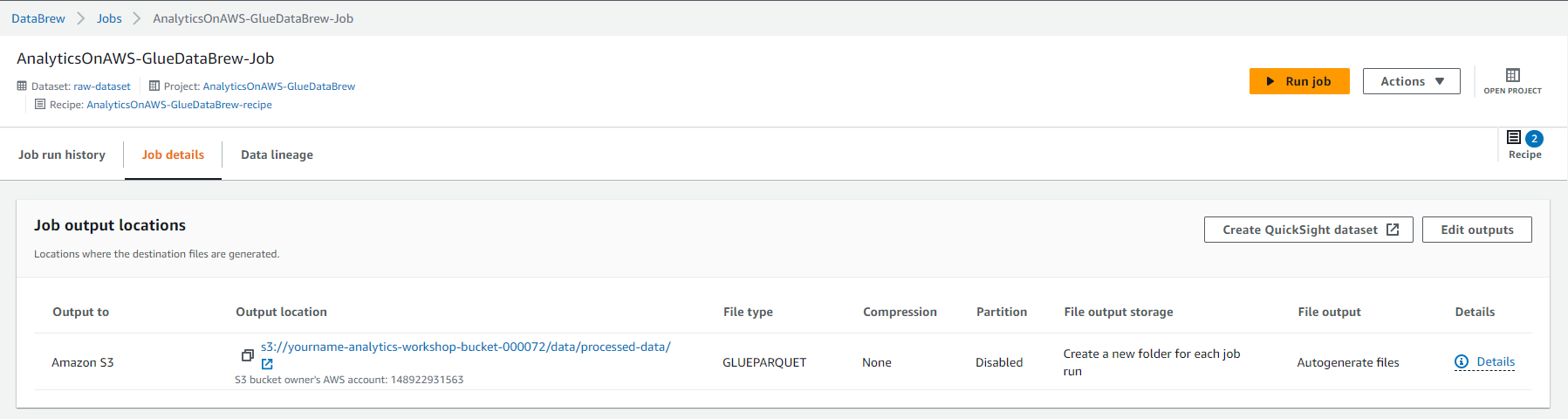
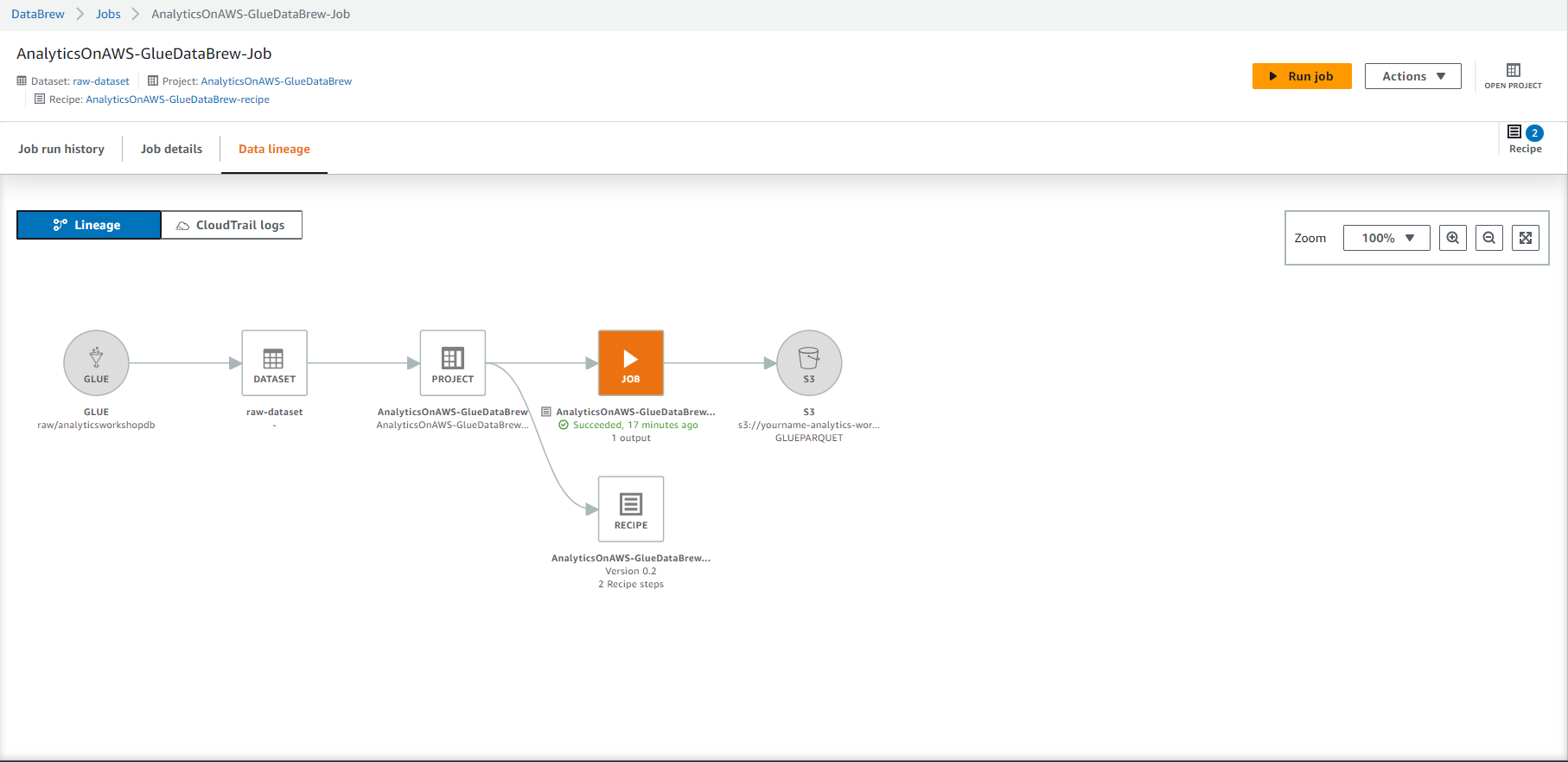
- job này nên mất khoảng 4-5 phút để hoàn thành, bạn nên nhìn thấy Succeeded status và Chọn vào 1 kết quả dưới cột Output.
